
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回はいよいよ「データカタログ作成」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue workflow
- Advanced Topics
AWS Glue Data Catalogとは
AWS公式サイトでは、以下のように説明されています。

- AWS Glue Data Catalog には、AWS Glue での抽出、変換、ロード (ETL) ジョブのソースおよびターゲットとして使用するデータへのリファレンスが含まれています。データウェアハウスやデータレイクを作成するには、このデータを分類する必要があります。
- AWS Glue Data Catalog は、データの場所、スキーマ、およびランタイムメトリクスへのインデックスです。データカタログ内の情報は、ETL ジョブの作成と監視に使用します。
- Data Catalog の情報はメタデータテーブルとして保存され、各テーブルが 1 つのデータストアを指定します。一般的には、クローラーを実行してデータストア内のデータのインベントリを行いますが、データカタログにメタデータテーブルを追加する別の方法もあります。
引用元:https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
データカタログはどのように編成されているか
データベースとテーブルの関係
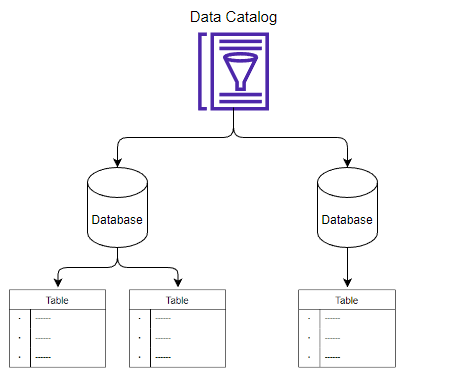
- Data Catalogは複数のデータベースを作成できる
- 各データベースに複数のテーブルを作成できる
- 各テーブルがデータに関する情報を保持する(スキーマ)
- 例えば、あるS3バケットに1ファイル存在する場合、1つのデータベースに1つのテーブルが存在するように表現する
テーブルの構造
- データロケーション、フォーマット
-

テーブル名や属するデータベース、データ形式、データの場所(ここではS3)といった情報
- スキーマ
-
例えばあるCSVファイルの構造について、カラム名とデータ型、パーティションキー、コメントで表現される


Glueデータカタログの代表的な作成方法
カタログの作成方法は主に3つ
SDKやCLIを用いてデータカタログ作成のAPIをコールする

マネジメントコンソールから手動でデータカタログを作成する
Glueクローラーを使って自動でデータカタログを作成する
ハンズオン
ハンズオン用のサンプルデータが提供されています。
Youtubeの概要欄リンクから事前に入手しておきます。
S3バケットにデータをアップロード
- バケットを作成します。
-
- バケットに3つのフォルダを作成します。
-
・athenaフォルダは、後ほど使用するAthenaのメタデータ保存用
・customerフォルダは、テーブルの元となるデータ格納先
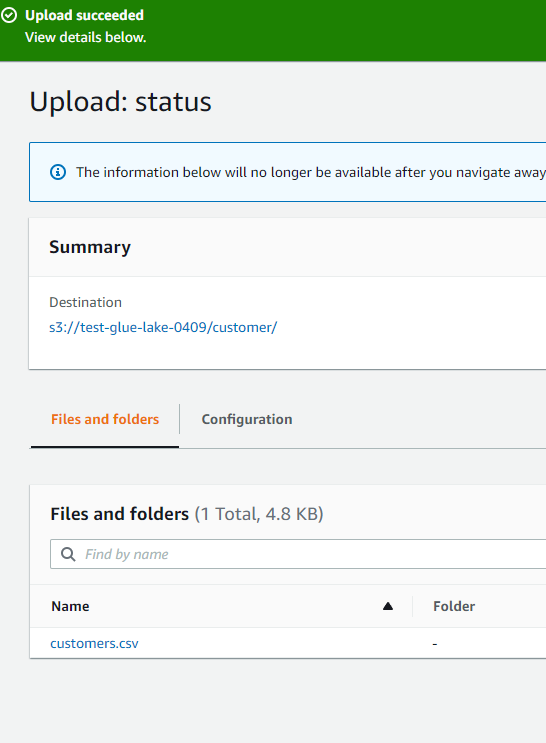
・scriptsフォルダは謎(笑)※今回のハンズオンでは使用しません - customerフォルダにcustomers.csvをアップロードします。
-
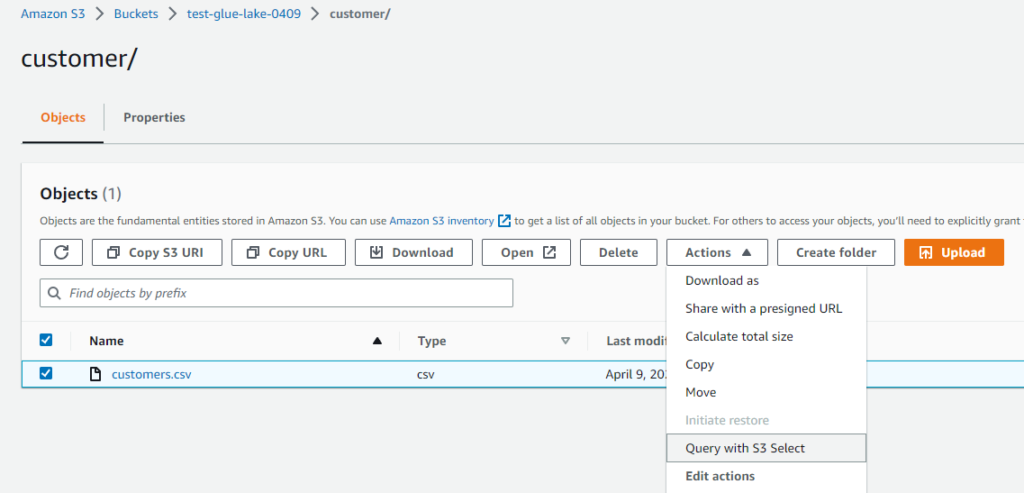
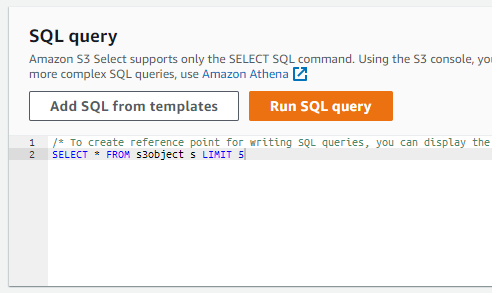
- 「Query with S3 Select」を選択します。
-
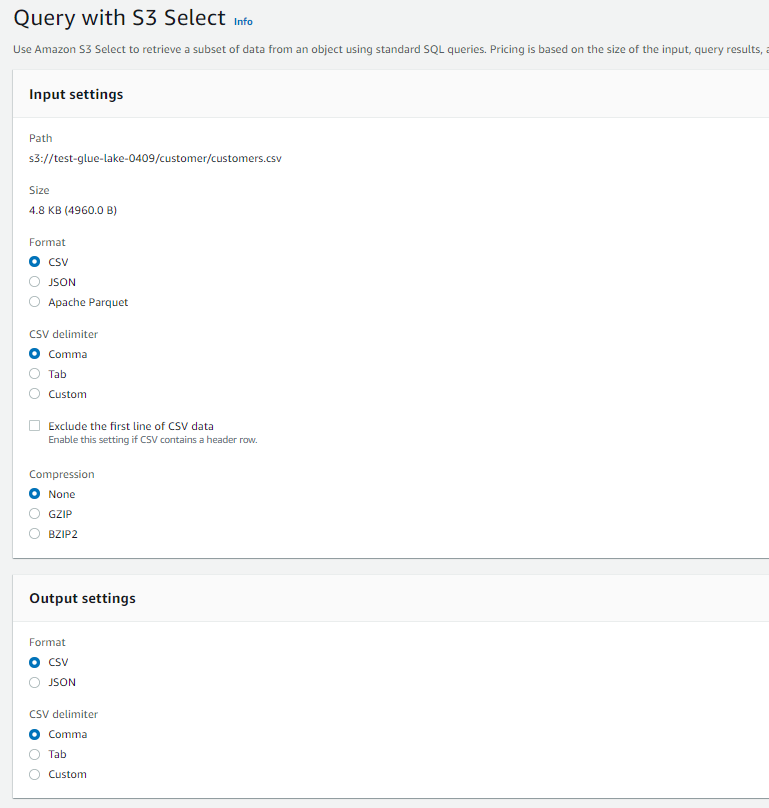
- すべてデフォルトでクエリを実行します。
-
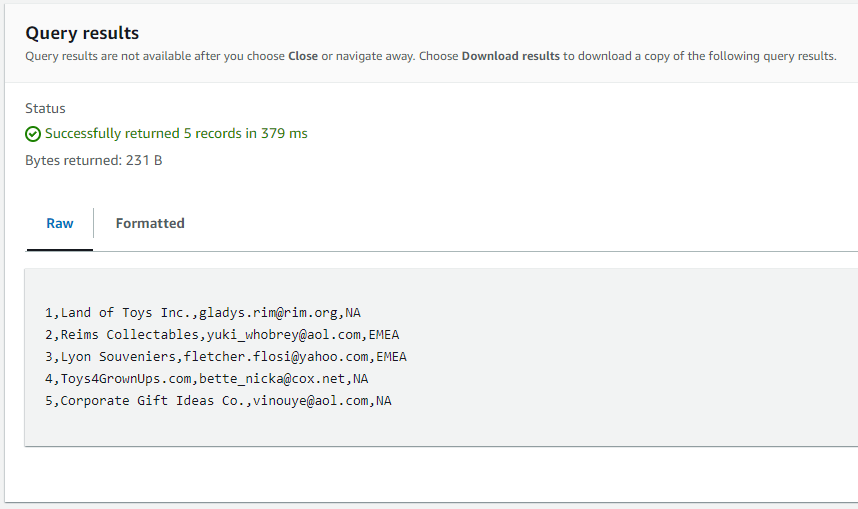
- クエリ結果が表示されました。
-
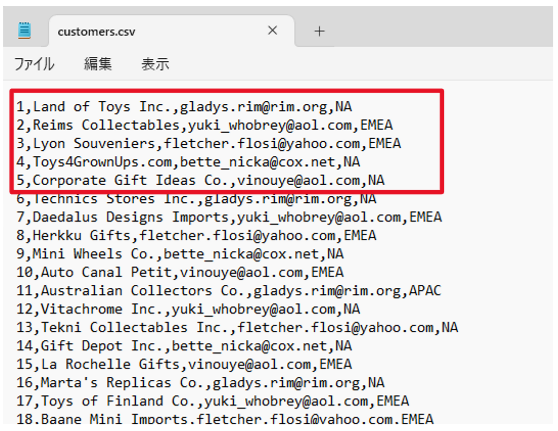
- customers.csvの先頭5行。想定通りですね。
-
AWS Lake Formation の設定
- Lake Formationを選択します。
-
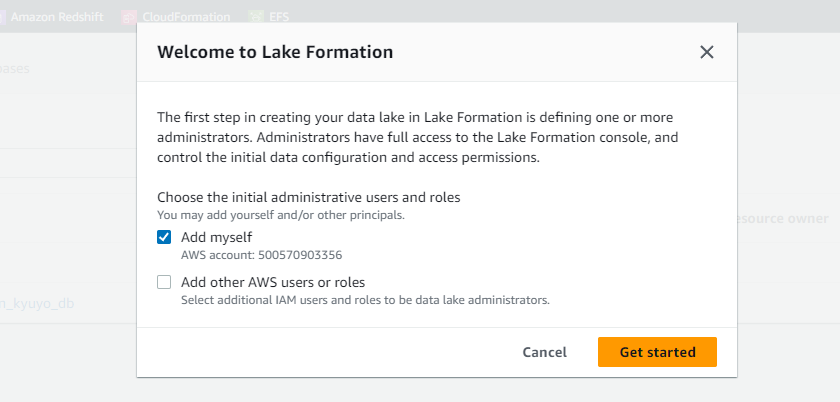
- 管理者として自身を追加します。
-
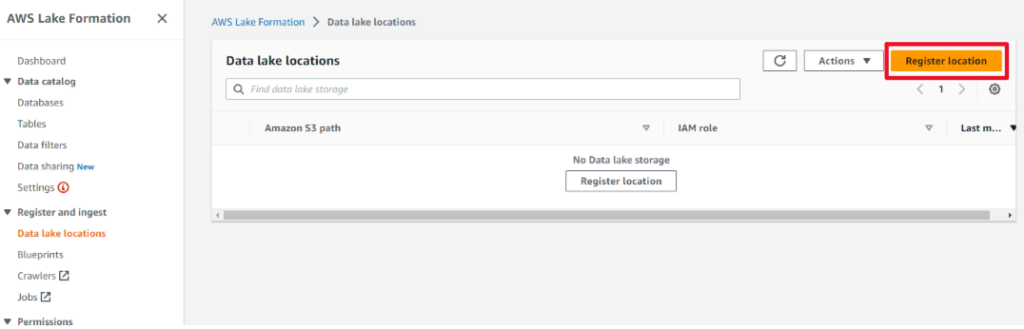
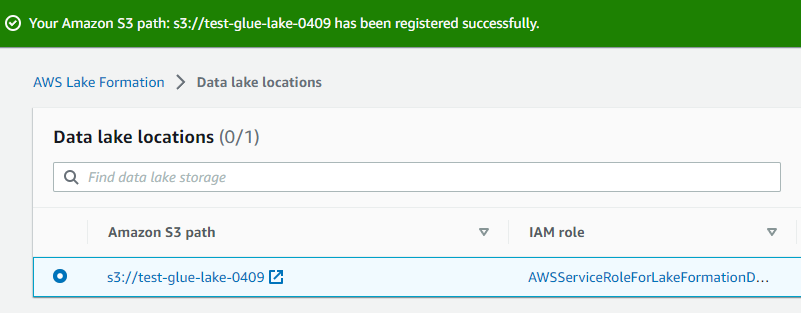
- データレイクロケーションを登録します。
-
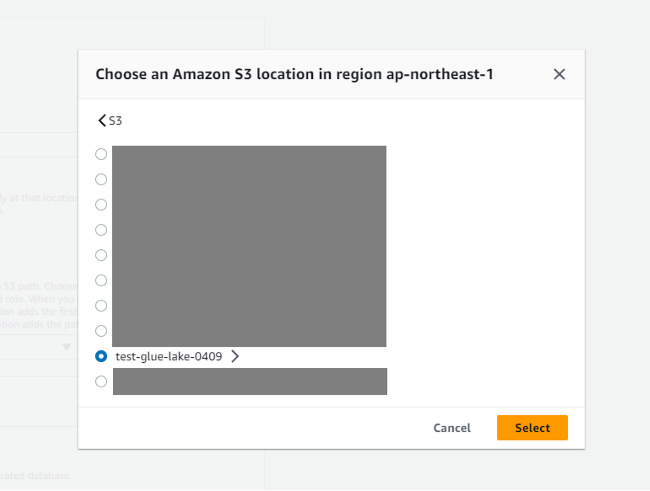
- 対象のフォルダを選択(ここではトップレベルのS3バケットを選択)します。
-
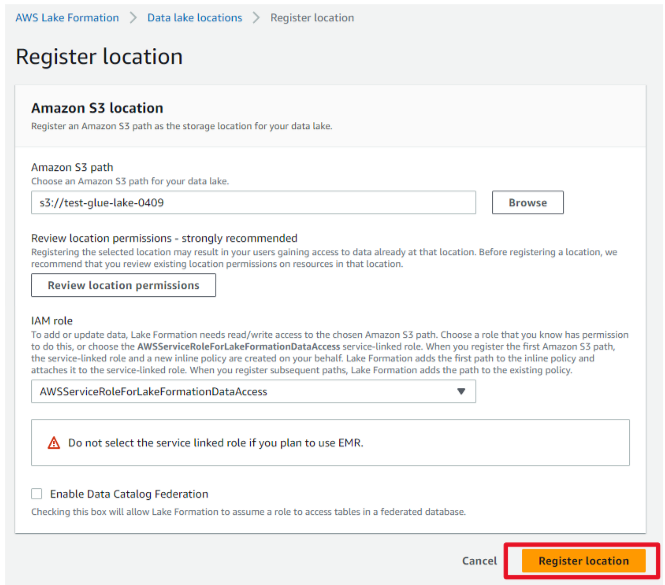
- 「Register location」を押下し、登録完了しました。
-
手動でデータベース作成
- 「Create database」を押下します。
-
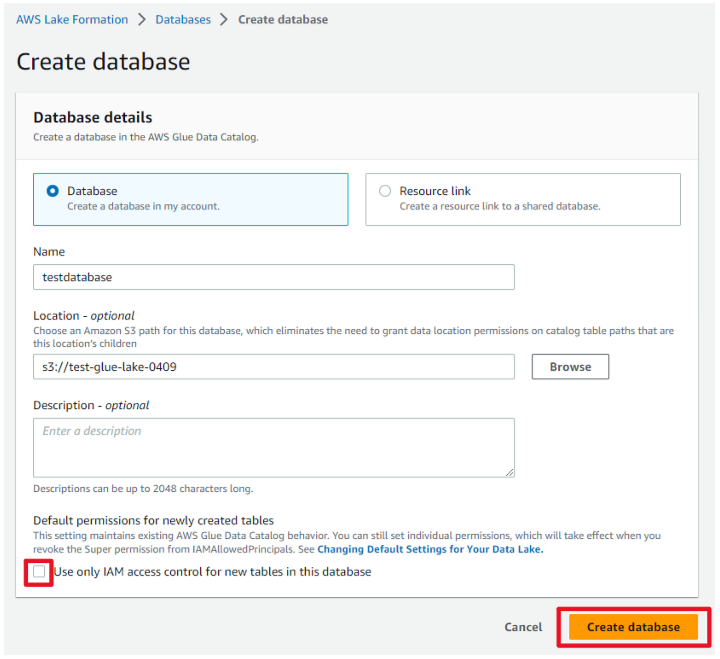
- データベース名とロケーションを入力して「Create database」を押下します。
(後にLake Formationのセキュリティを使用するため、IAMのアクセスコントロールをオフにします。) -
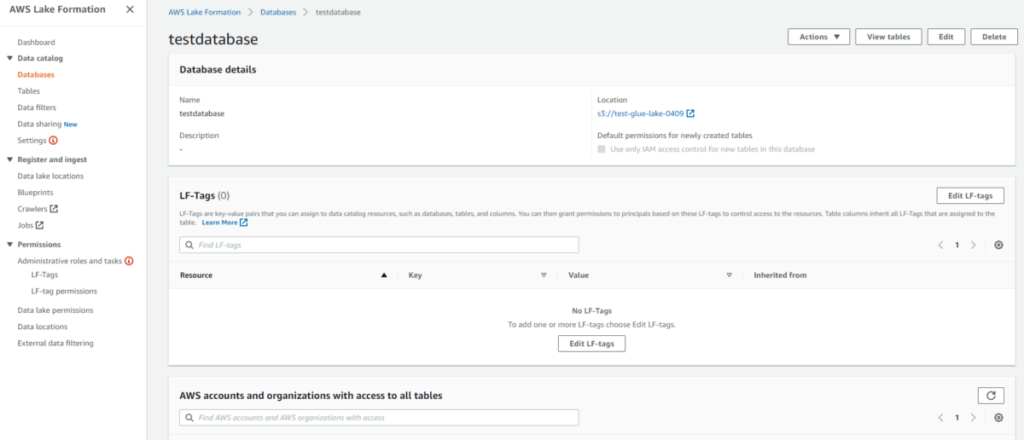
- データベースを作成できました。
-
手動でテーブル作成
作成したデータベースに顧客テーブルを作成します。
このテーブルが、S3バケットに格納したデータ(customers.csv)のカタログになります。
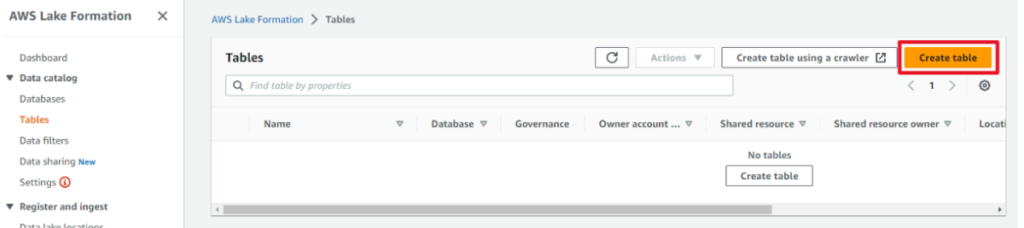
- 「Create table」を押下します。
-
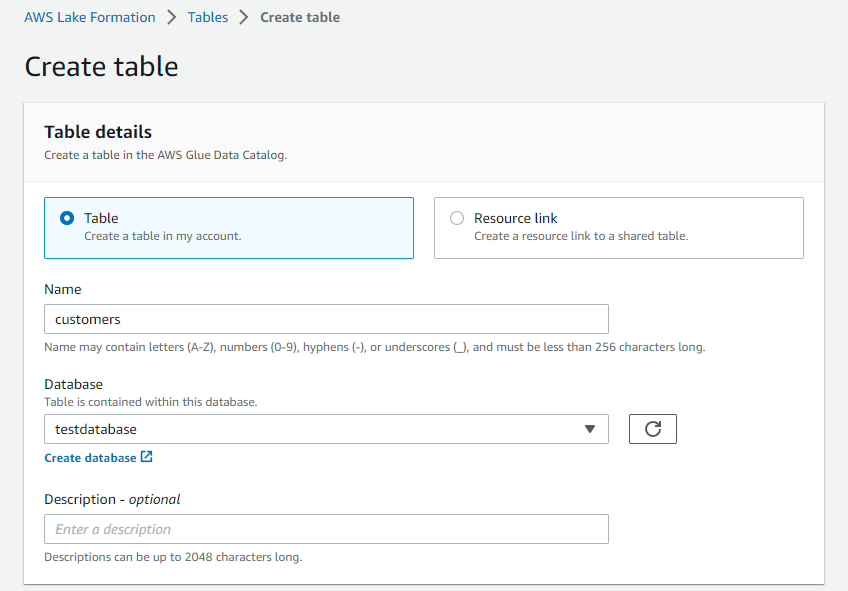
- テーブル情報を入力していきます。
-
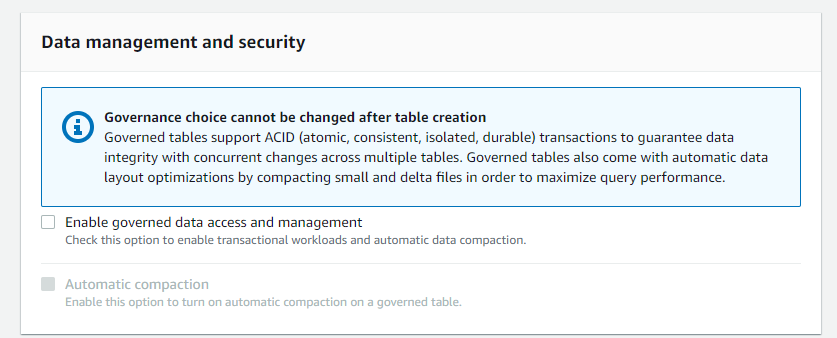
今回「Data management and security」はオフのままで。
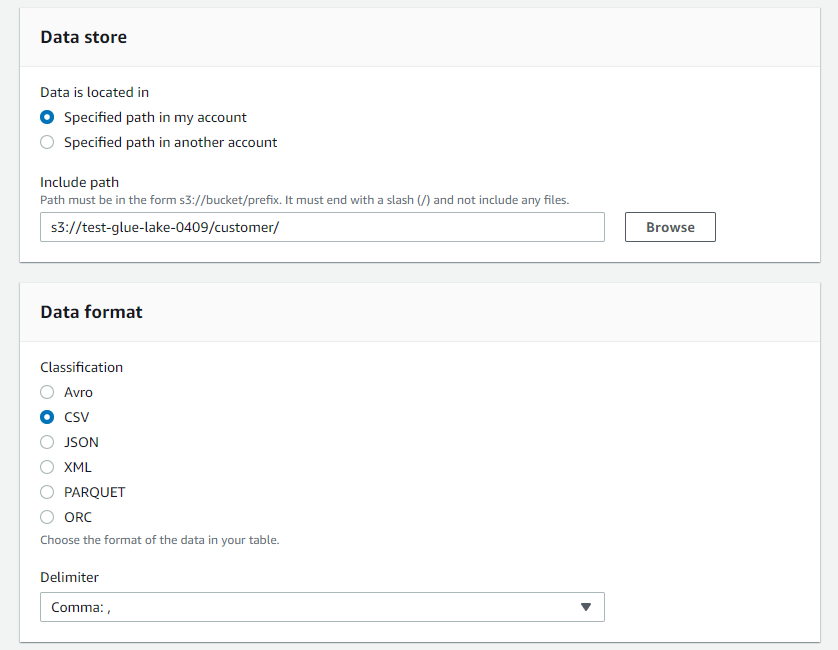
データストアはcustomerフォルダを、データフォーマットはcsvをセット。
今回、スキーマは手動で作成します。
クローラーを使用している場合は自動で識別されますが、後のセクションで出てくるみたいです。
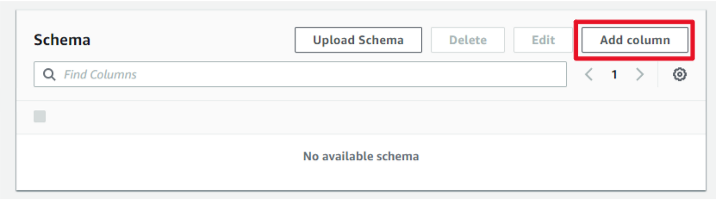
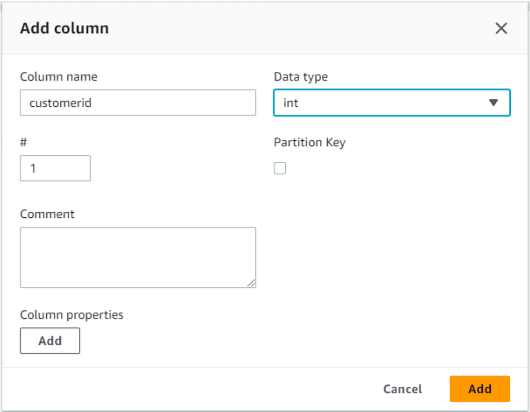
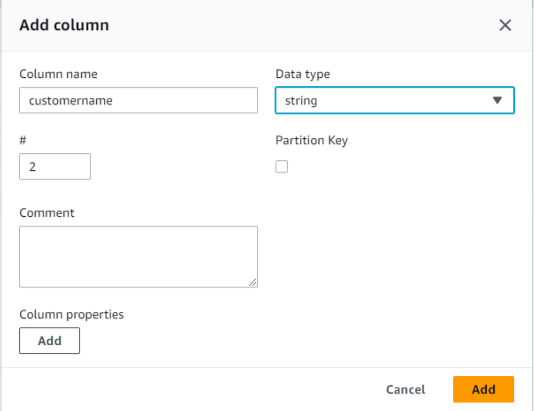
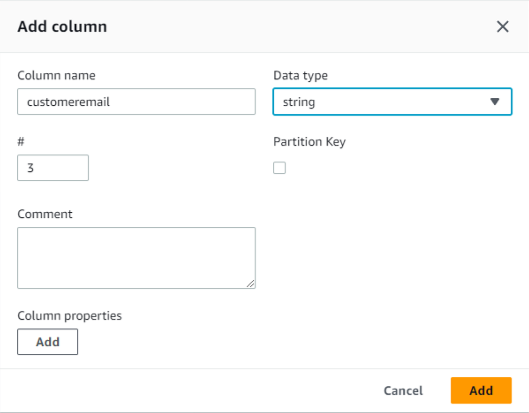
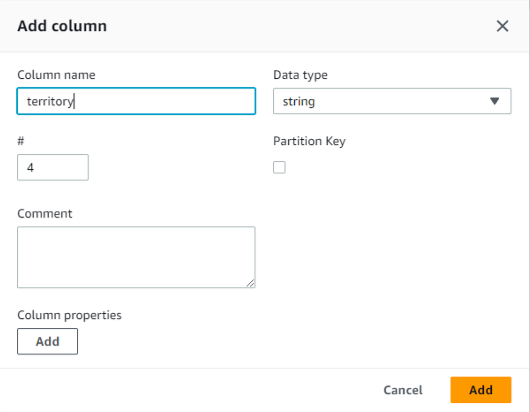
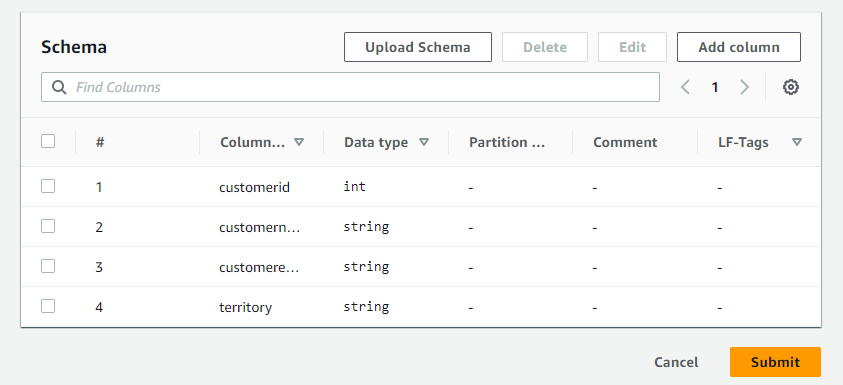
jsonファイルをアップロードして定義することもできますが、ここでは地道にカラムを追加します。4カラム追加してスキーマが出来ました。
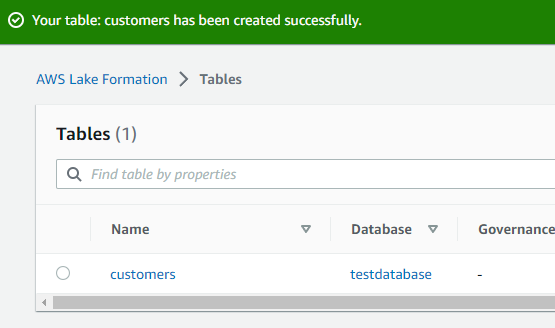
以上でテーブル作成に必要な入力は完了。「Submit」します。テーブル作成が完了しました。
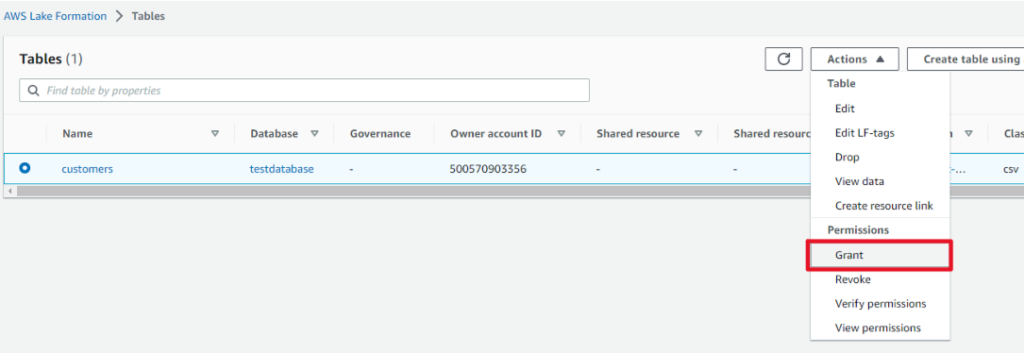
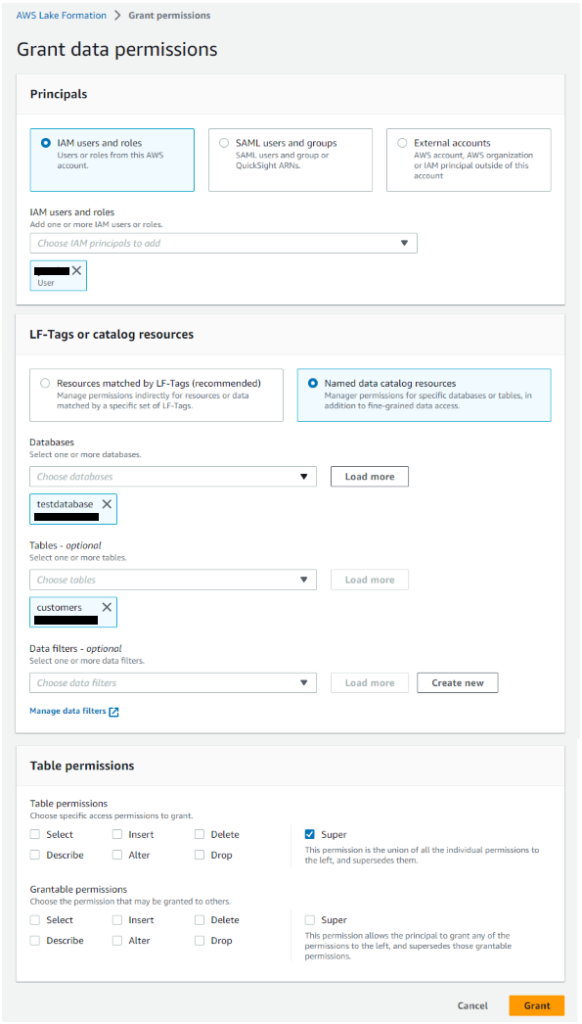
- テーブルへのアクセス許可を行います。
-
Lake Formationのセキュリティを使用するようにしましたが、現在ログインしているIAMユーザにはcustomersテーブルへのアクセス権がないので付与します。
IAMユーザを選択。データベースとテーブルは自動入力されました。
今回はLFタグではなく、名前付きデータカタログリソースを使用します。
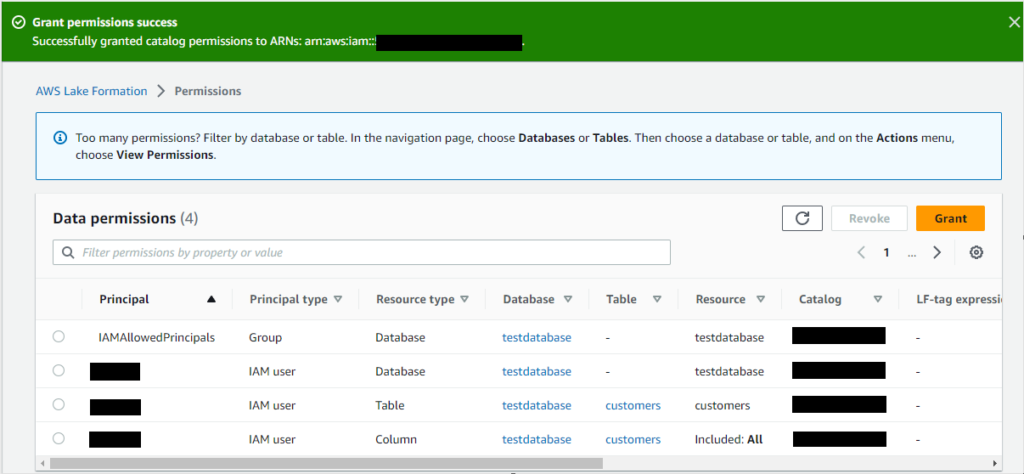
テーブルパーミッションは、ここでは管理者権限の「Super」を選択します。 - IAMユーザへのアクセス付与が完了しました。
-
フル権限です(笑)。
Athenaでデータ参照
- Athenaを選択します。
-
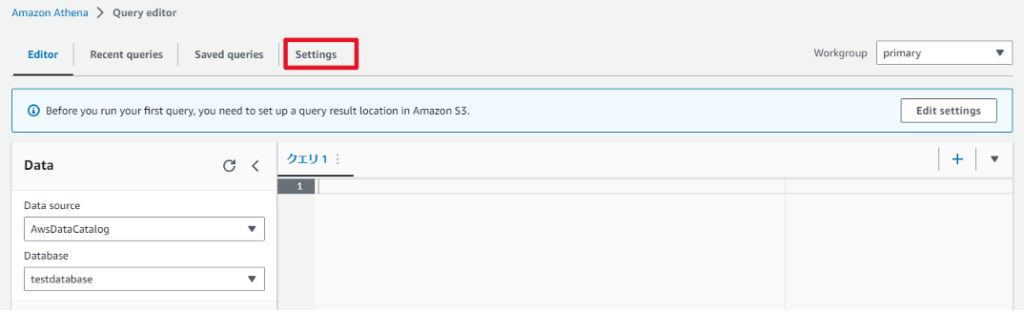
- 「Setting」タブを開きます。
-
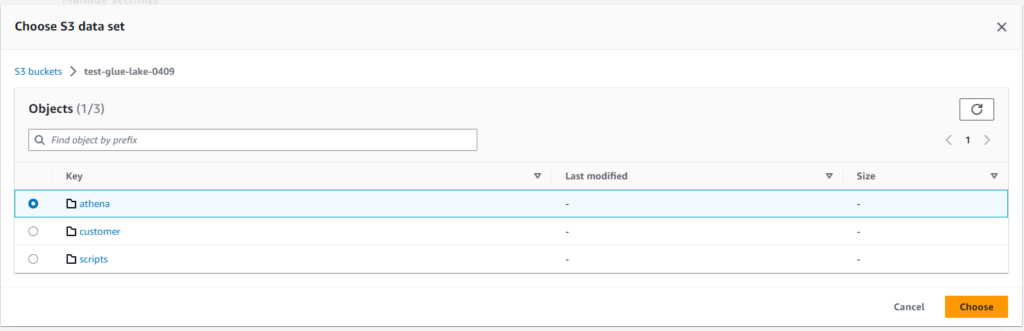
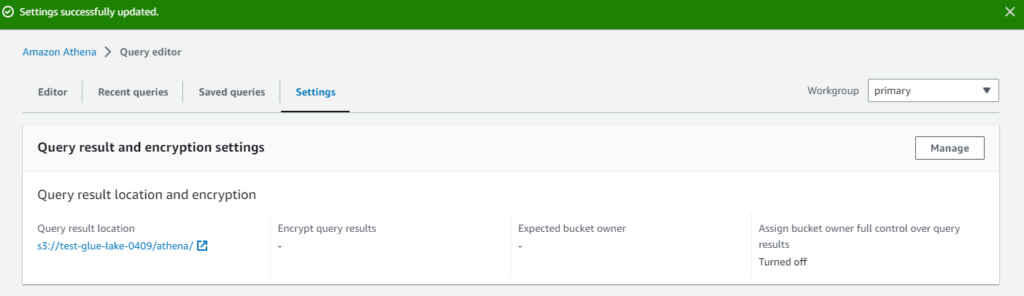
Athenaはサーバレスサービスですが、クエリ結果や一時的な値を格納する場所としてS3バケットを指定して同期するようにします。
最初に作ったS3バケットの「athena」フォルダを選択して保存しました。設定完了です。
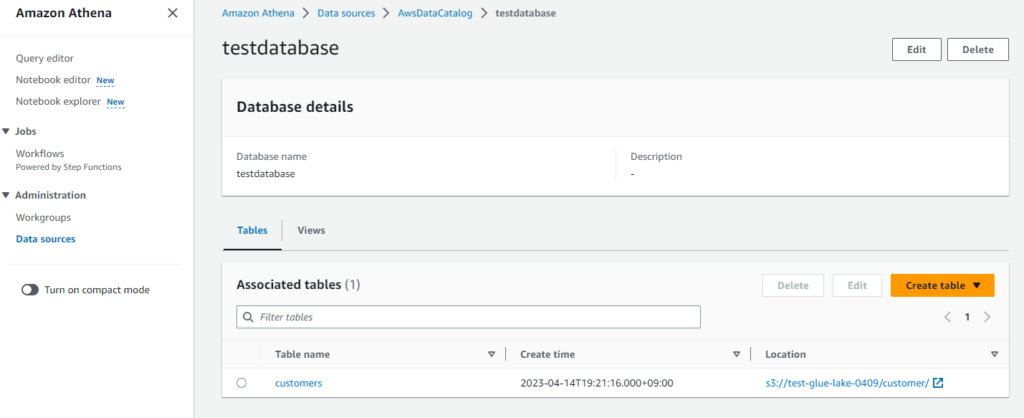
- データソースを確認します。
-
「AwsDataCatalog」に作成したデータベースとcustomersテーブルが存在することを確認しました。
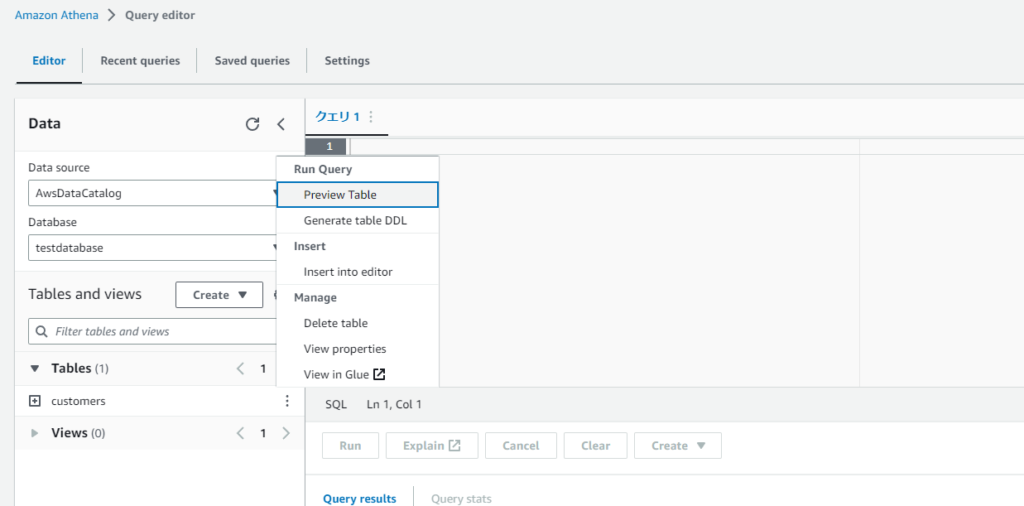
- クエリエディタに戻り、customersテーブルに対して「Preview Table」を選択します。
-
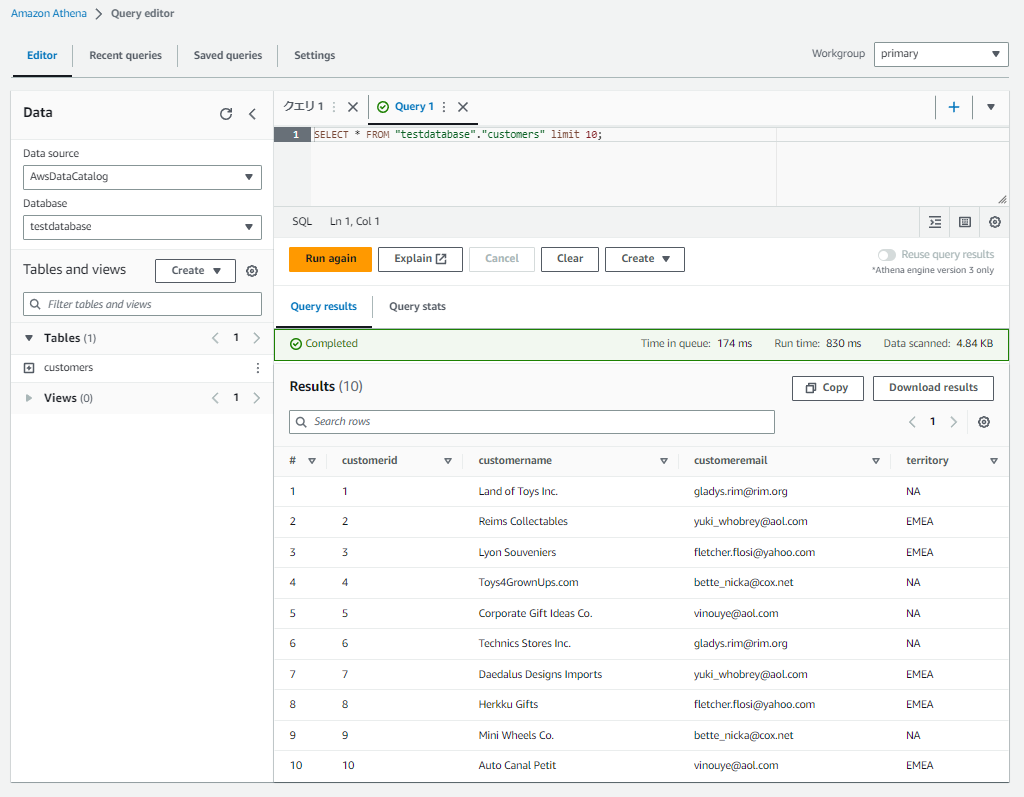
- 無事、customersテーブルをクエリすることができました。
-
おわりに
今回は以下を行いました。
- S3へのデータアップロード
- Lake FormationによるGlueデータカタログ(データベース、テーブル)作成
- Lake Formationを用いてテーブルへのアクセス許可
- Athenaによるテーブルへのクエリ発行
実施する中で、以下が気になりました。
・ Lake Formationを使用せず、既にGlueデータカタログを作っていた場合の挙動
・ customerフォルダに複数のCSVが存在する場合の挙動
(今回、customerフォルダにはcustomers.csvしか存在しなかった)
ひとまずここに残しておき、今後紐解いていきたいと思います。


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.2) 前回のハンズオンの続きです。 […]