
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回は「Glueクローラー」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue Workflow
- Advanced Topics
Glueクローラーとは

データストアを自動的に回り、AWS Glue カタログでデータストアのテーブルを作成するために使用されます。
サーバレスです。
GlueクローラーはAWS Glueの機能で、データカタログを自動で作成します。
非常に多くのデータセットがある場合は助かる機能です。
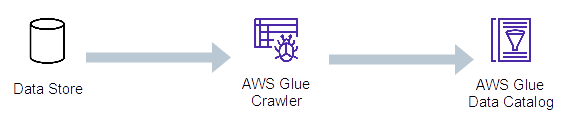
クローラーがサポートするデータストア
Glueクローラーがは以下のようなデータストアをサポートします。

クローラーの分類子
- 分類子は、データストアのデータを読み取りフォーマットを識別してスキーマを作成するため、クローラーによって使用されます
- クローラーは自動的に適する分類子を使いますが、分類子を選択することはできません。
- ビルトインの分類子がたくさんあります。またカスタム分類子を作成することもできます
- もし分類子がデータフォーマットを認識できない場合、間違ったスキーマが作成される場合があります。
ビルトイン分類子
- AVRO
- ORC
- PARQUET
- JSON
- BSON
- XML
- CSV
- JDBC Sources
- 他
カスタム分類子
- CSV
- XML
- JSON
- Grok Pattern
データストアにJDBC接続するためのGlueコネクション
JDBCデータストアをクロールする際は、JDBC接続文字列やクレデンシャルで作成したGlueコネクションを用いてJDBCデータストアに接続します。
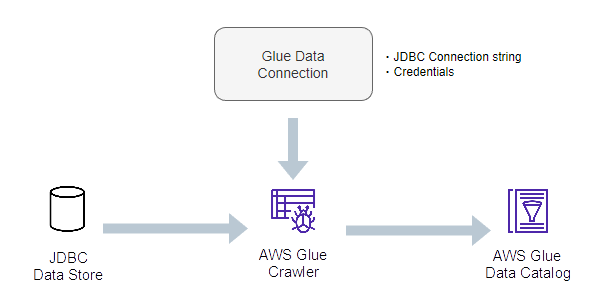
Glueクローラーの実行方法

コンソールからオンデマンドで実行できます。CLIやSDKでAPIを呼び出すことでもクローラーを実行できます。
また、クローラーに付随するスケジュール機能を使い、スケジュールに基づいてクローラーを実行できます。
最後に、クローラーをパイプラインまたはワークフローの一部として実行することもできます。
ハンズオン
今回は以下がポイントです。
- RDSのデータベースに作成されたテーブルをGlueクローラーでカタログ化する
提供された資材のうち、今回は「4_Glue_Crawler」を用います。
[IAM] クローラー向けのロール作成
![[IAM] クローラー向けのロール作成開始](https://techuplabo.blog/wp-content/uploads/2023/04/image-141.png)
![[IAM] クローラー向けのロール作成1](https://techuplabo.blog/wp-content/uploads/2023/04/image-142.png)
![[IAM] クローラー向けのロール作成2](https://techuplabo.blog/wp-content/uploads/2023/04/image-143.png)
![[IAM] クローラー向けのロール作成3](https://techuplabo.blog/wp-content/uploads/2023/04/image-144.png)
ロール名を入力したらあとはデフォルトのまま「Create role」します。
![[IAM] クローラー向けのロール作成4](https://techuplabo.blog/wp-content/uploads/2023/04/image-145.png)
[Lake Formation] クローラー向けの権限設定
前回のハンズオンで、Lake Formationにデータベースを作成済みです。
![[Lake Formation] クローラー向けの権限設定1](https://techuplabo.blog/wp-content/uploads/2023/04/image-146.png)
Glueクローラーにテーブルを作成できるよう許可を与えます。
![[Lake Formation] クローラー向けの権限設定2](https://techuplabo.blog/wp-content/uploads/2023/04/image-147.png)
先程作成したIAMロール(test_crawler_role)とデータベース(testdatabase)を指定します。
![[Lake Formation] クローラー向けの権限設定3](https://techuplabo.blog/wp-content/uploads/2023/04/image-148.png)
クローラーにテーブル作成権限を与えるため「Create table」をチェックしてGrantします。
![[Lake Formation] クローラー向けの権限設定4](https://techuplabo.blog/wp-content/uploads/2023/04/image-149.png)
登録できました。
Glueクローラーがこの特定のロールで実行されるときに、テーブル作成権限があるということになります。
![[Lake Formation] クローラー向けの権限設定5](https://techuplabo.blog/wp-content/uploads/2023/04/image-150.png)
[RDS] Auroraインスタンス構築
インスタンス構築
「Launch_RDS_Database_Instance.pdf」の手順書を参考に進めます。
現在はServerless v2が主流なのですが、Data APIを使えずクエリエディタで接続できません。
v2の使用は今回の主旨ではないので、古いですがv1を使えるバージョンを選択しました。
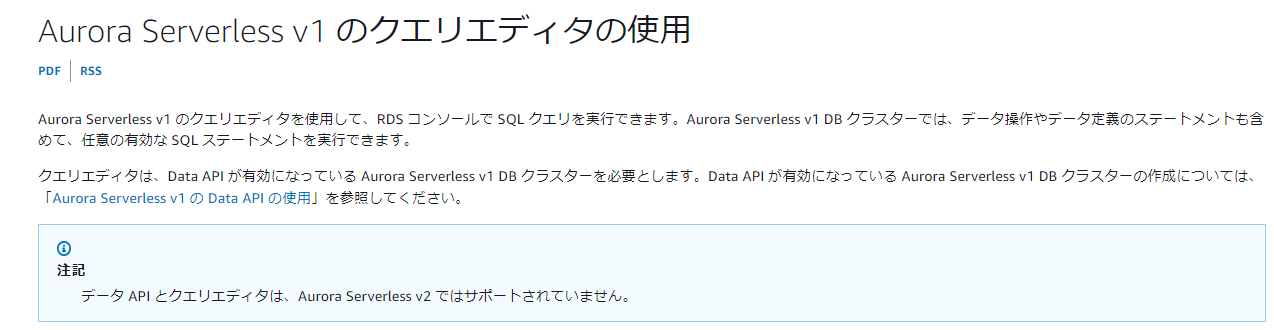
引用元:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/query-editor.html
数分待つとStatusが「Available」となり起動完了です。
![[RDS] Auroraインスタンス構築](https://techuplabo.blog/wp-content/uploads/2023/04/image-163.png)
テーブル作成、データ登録
クエリエディタを起動します。
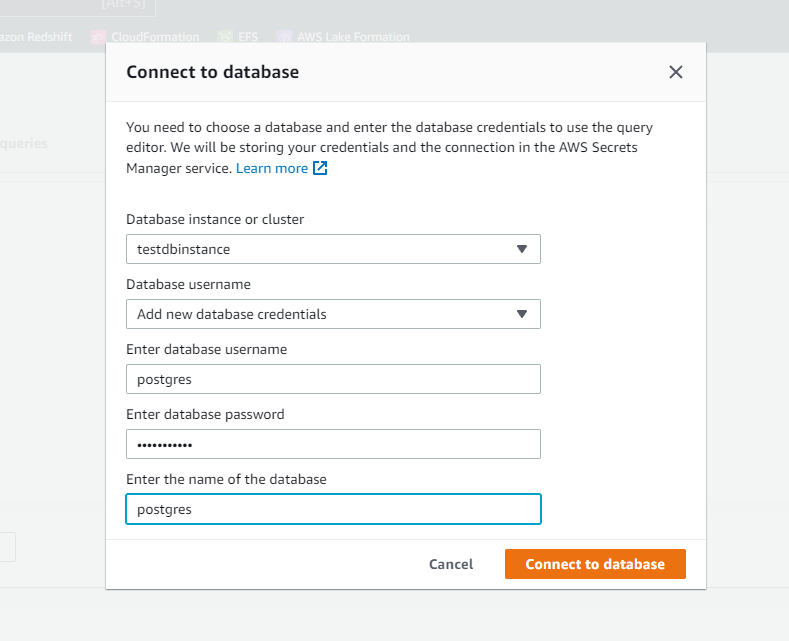
接続できました。
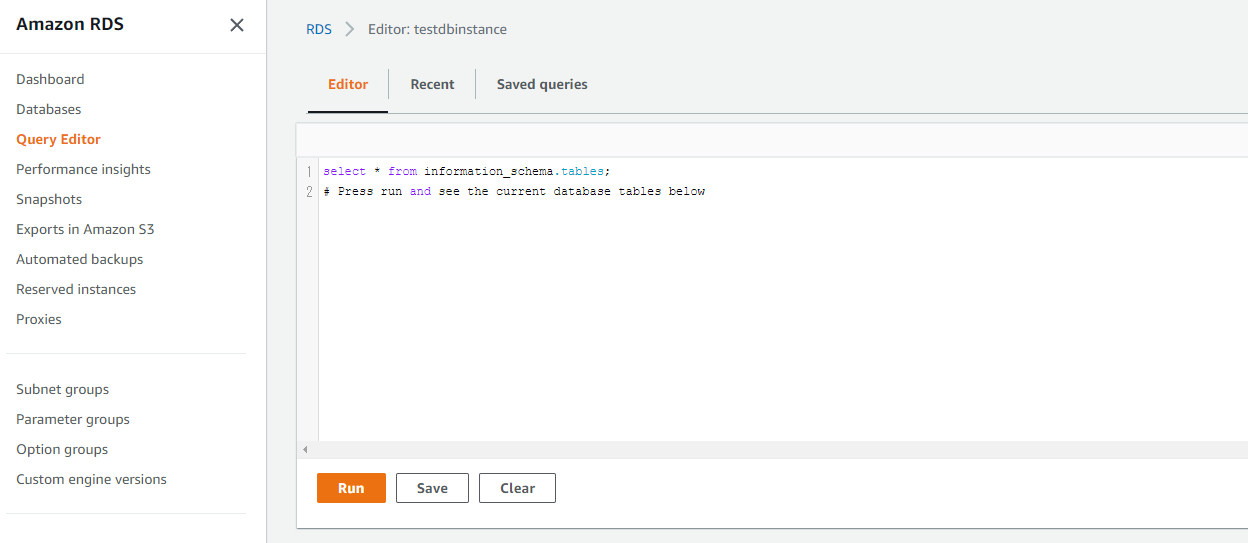
「RDS_Table_Data_Create_Script.sql」に沿ってSQLを実行します。
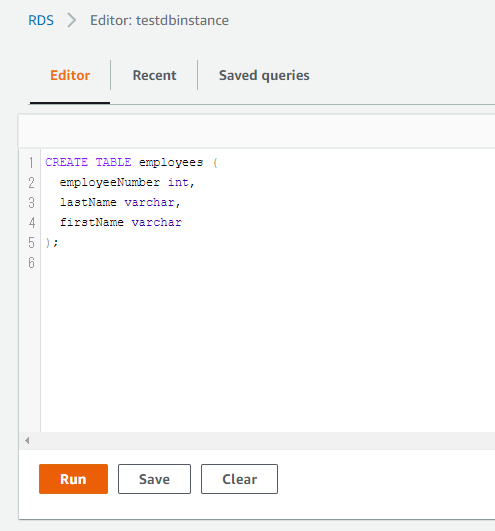
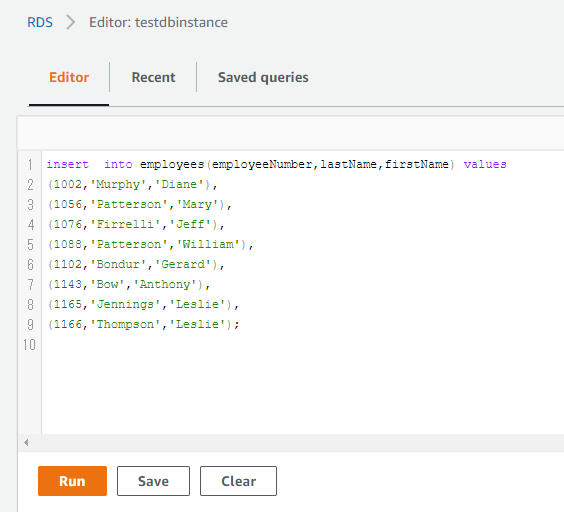
想定どおりレコードを登録できているか確認します。
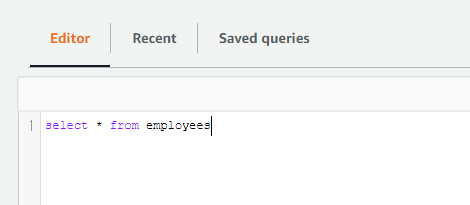
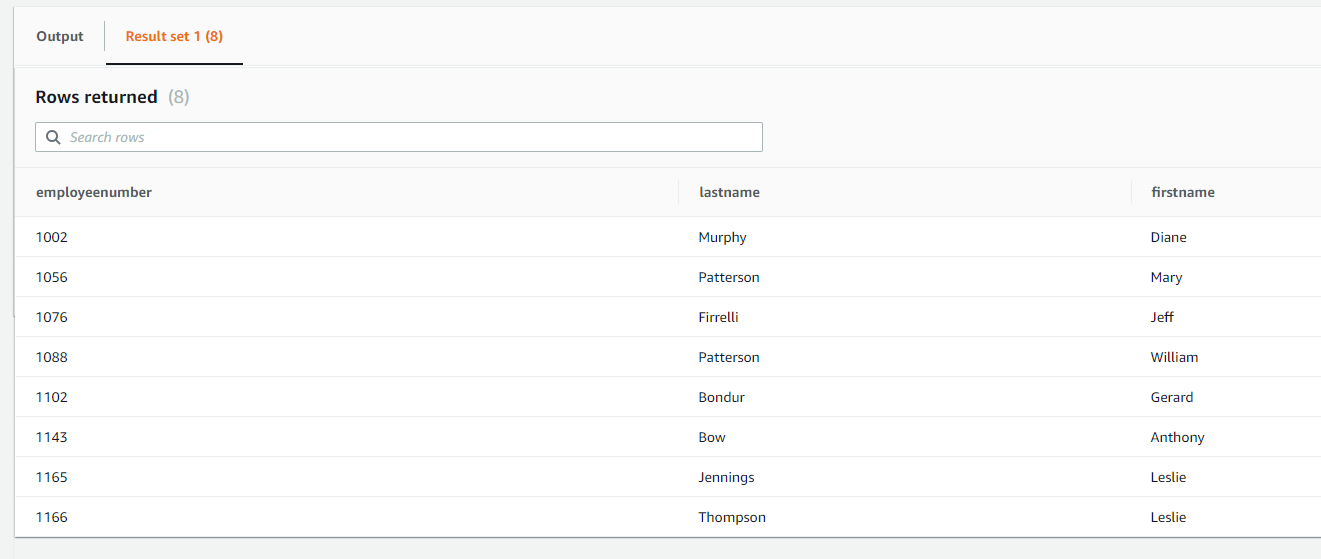
以上でRDSインスタンスを起動し、テーブル作成とレコード登録を完了しました。
[Glue] コネクション作成&テスト接続
AWS Glueを開きます。
![[Glue] コネクション作成&テスト接続1](https://techuplabo.blog/wp-content/uploads/2023/04/image-174.png)
![[Glue] コネクション作成&テスト接続2](https://techuplabo.blog/wp-content/uploads/2023/04/image-175.png)
jdbc:protocol://host:port/db_name
jdbc:postgresql://{host}:5432/postgres
host(エンドポイント)は、RDSのデータベース情報から確認できます。
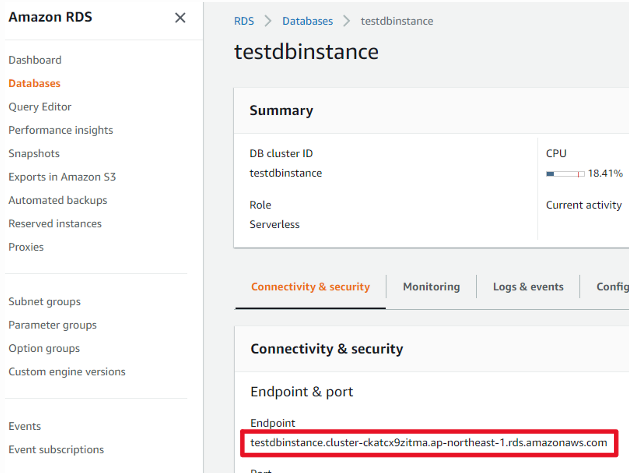
![[Glue] コネクション作成&テスト接続3](https://techuplabo.blog/wp-content/uploads/2023/04/image-183.png)
接続成功するまでにハマったので「Glueコネクション」についてメモ
・サブネットはプライベート(接続失敗したときはパブリックだった)

・サブネットのセキュリティグループ
参考:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/setup-vpc-for-glue-access.html

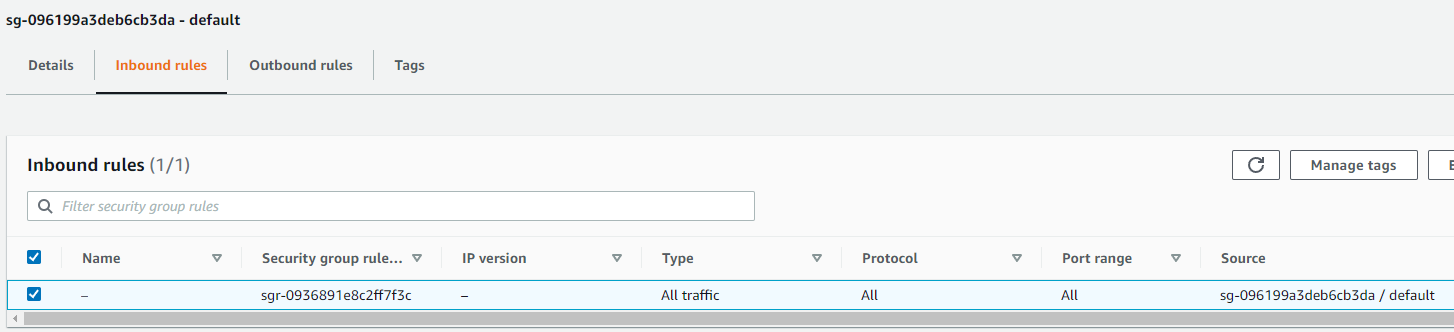
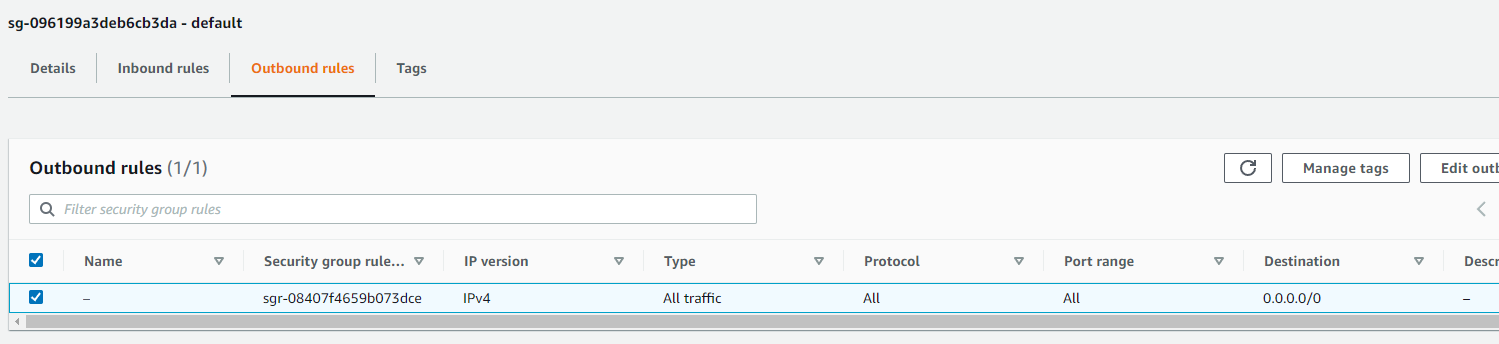
コネクションを作成完了しました。
![[Glue] コネクション作成&テスト接続4](https://techuplabo.blog/wp-content/uploads/2023/04/image-178.png)
テスト接続を行います。
![[Glue] コネクション作成&テスト接続5](https://techuplabo.blog/wp-content/uploads/2023/04/image-179.png)
前回のハンズオンで作ったIAMロールを選択します。
![[Glue] コネクション作成&テスト接続6](https://techuplabo.blog/wp-content/uploads/2023/04/image-182.png)
RDSへ接続成功です。
![[Glue] コネクション作成&テスト接続7](https://techuplabo.blog/wp-content/uploads/2023/04/image-181.png)
[Glue] クローラー作成&実行
![[Glue] クローラー作成&実行1](https://techuplabo.blog/wp-content/uploads/2023/04/image-189.png)
![[Glue] クローラー作成&実行2](https://techuplabo.blog/wp-content/uploads/2023/04/image-190.png)
![[Glue] クローラー作成&実行3](https://techuplabo.blog/wp-content/uploads/2023/04/image-191.png)
![[Glue] クローラー作成&実行4](https://techuplabo.blog/wp-content/uploads/2023/04/image-192.png)
![[Glue] クローラー作成&実行5](https://techuplabo.blog/wp-content/uploads/2023/04/image-193.png)
![[Glue] クローラー作成&実行6](https://techuplabo.blog/wp-content/uploads/2023/04/image-194.png)
![[Glue] クローラー作成&実行7](https://techuplabo.blog/wp-content/uploads/2023/04/image-196.png)
Glueクローラーを作成しました。
![[Glue] クローラー作成&実行8](https://techuplabo.blog/wp-content/uploads/2023/04/image-197.png)
[Glue] クローラー実行
![[Glue] クローラー作成&実行9](https://techuplabo.blog/wp-content/uploads/2023/04/image-198.png)
数分待ちます。
![[Glue] クローラー作成&実行10](https://techuplabo.blog/wp-content/uploads/2023/04/image-199.png)
![[Glue] クローラー作成&実行11](https://techuplabo.blog/wp-content/uploads/2023/04/image-200.png)
およそ5分。終わったようです。
![[Glue] クローラー作成&実行12](https://techuplabo.blog/wp-content/uploads/2023/04/image-201.png)
[Glue] テーブル確認
RDSから吸い上げた「postgres_public_employees」テーブルが追加されていました。
![[Glue] テーブル確認](https://techuplabo.blog/wp-content/uploads/2023/04/image-202.png)
[Lake Formation]テーブル確認
Lake Formationで見てみます。こちらも同様に追加されていました。
![[Lake Formation]テーブル確認](https://techuplabo.blog/wp-content/uploads/2023/04/image-203.png)
おわりに
今回は以下の手順で、LakeFormationのよるアクセス制御を学びました。
- Glueクローラー用のIAMロール作成
- Lake Formationでクローラーにデータカタログのテーブル作成を許可
- RDSにGlueクローラーでJDBC接続し、自動でデータカタログを作成
単にクローラー作成するだけと思いきや、Glueコネクションのサブネットセキュリティグループで思わずハマってしまいました。
後続のハンズオンではもう少し設定変更が必要かもしれませんが、今回の設定内容を備忘録として残しておきます。
参考:VPCおよびエンドポイント
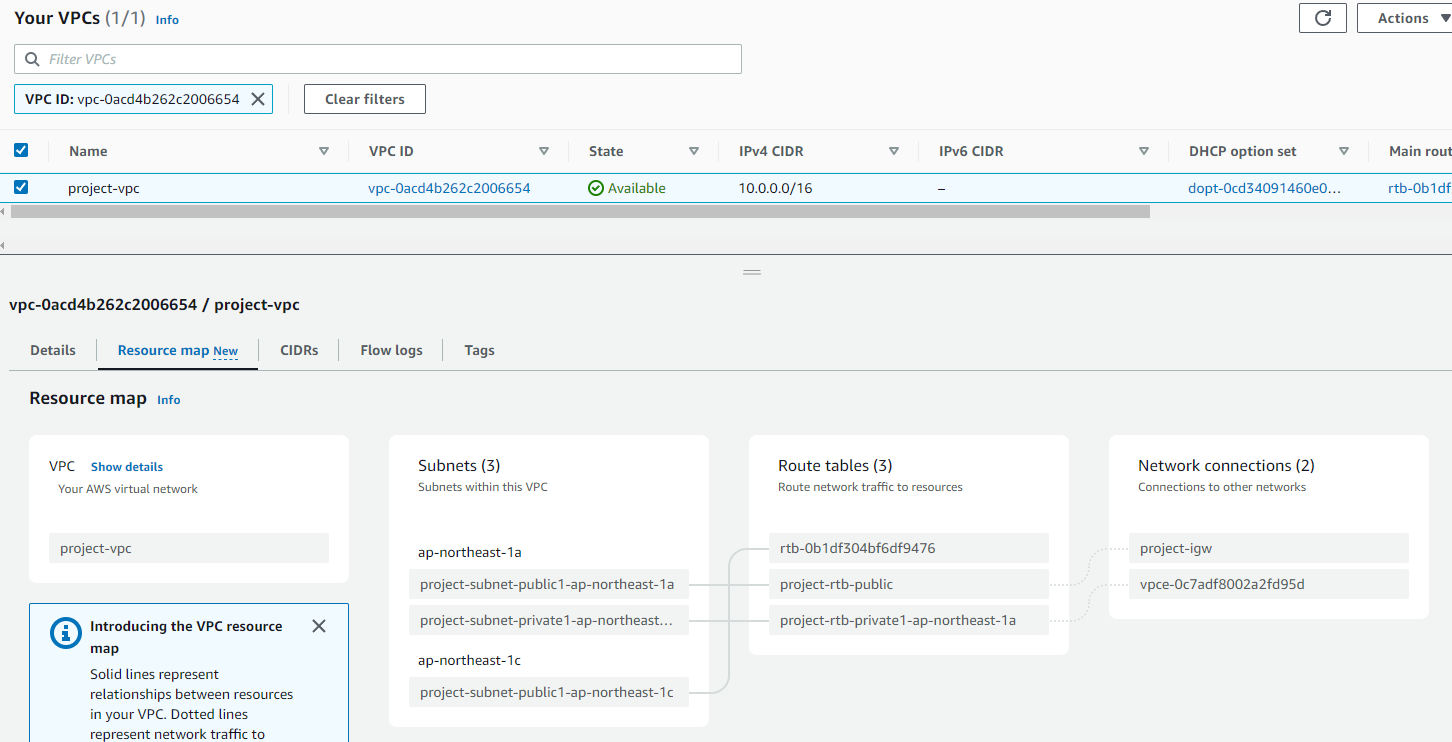
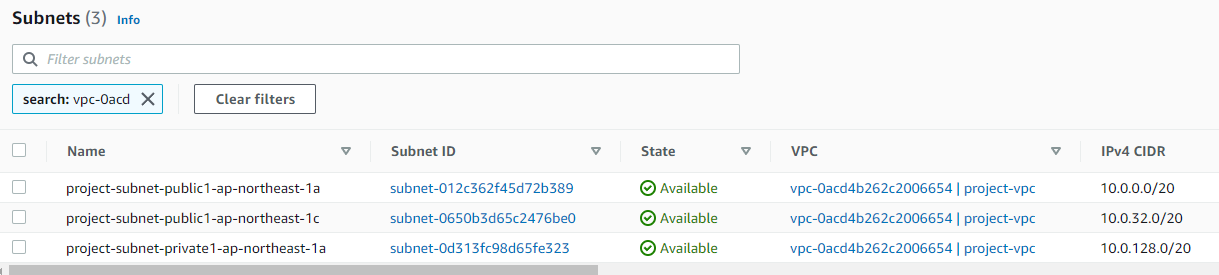

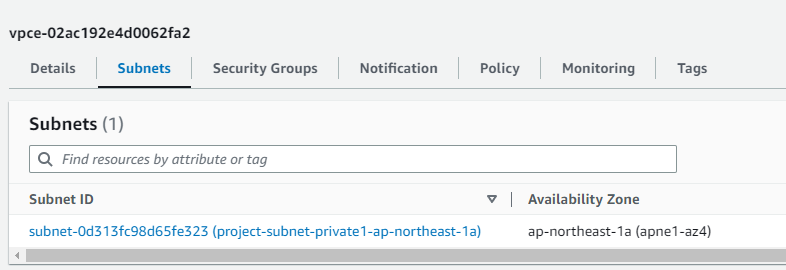
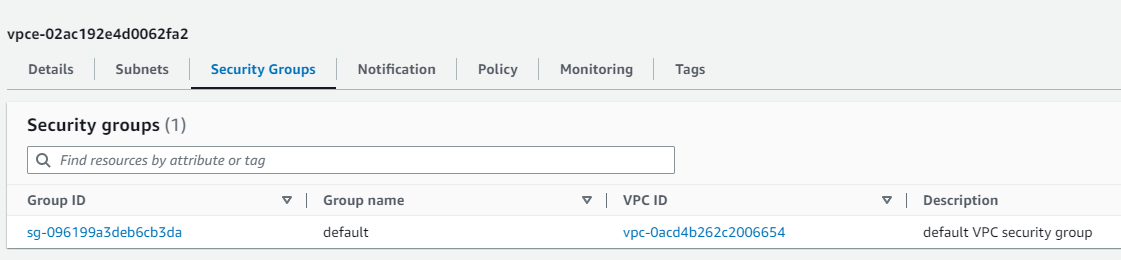
↓のエンドポイントはAuroraサーバレスを作成したら自動生成されました(Aurora削除すると消えます)
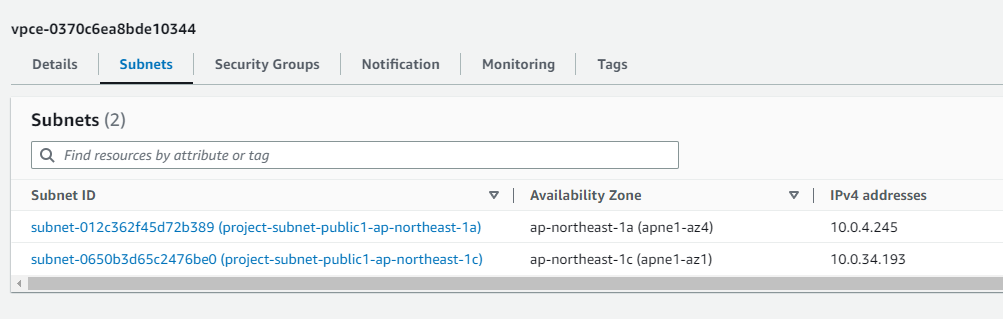
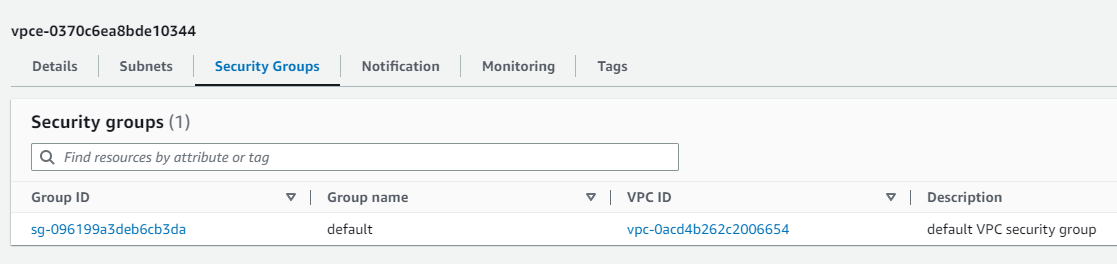
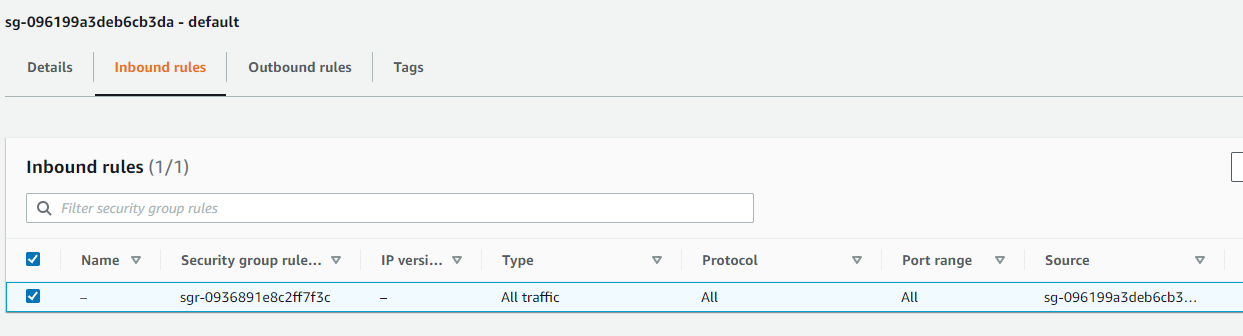
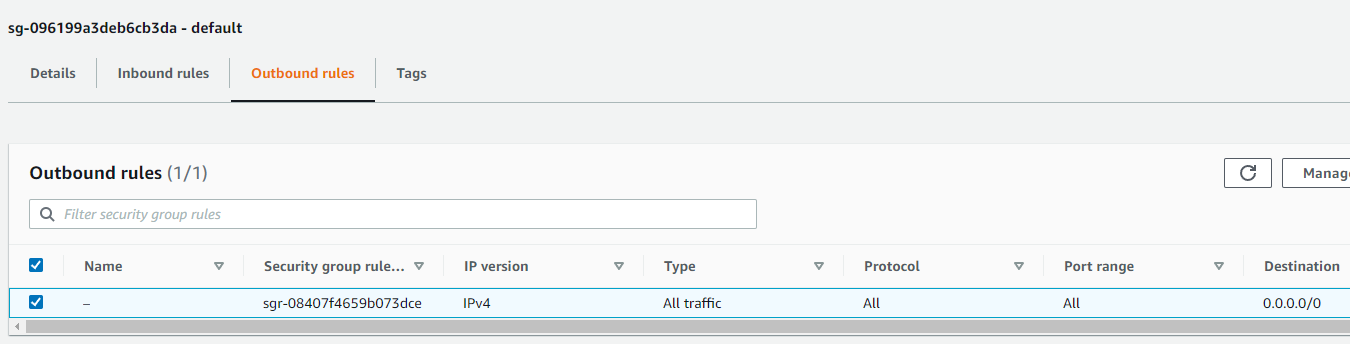
参考:RDS
Auroraサーバレス v1(PostgreSQL互換、11.16)。
セキュリティグループはVPCエンドポイントのSGでした。
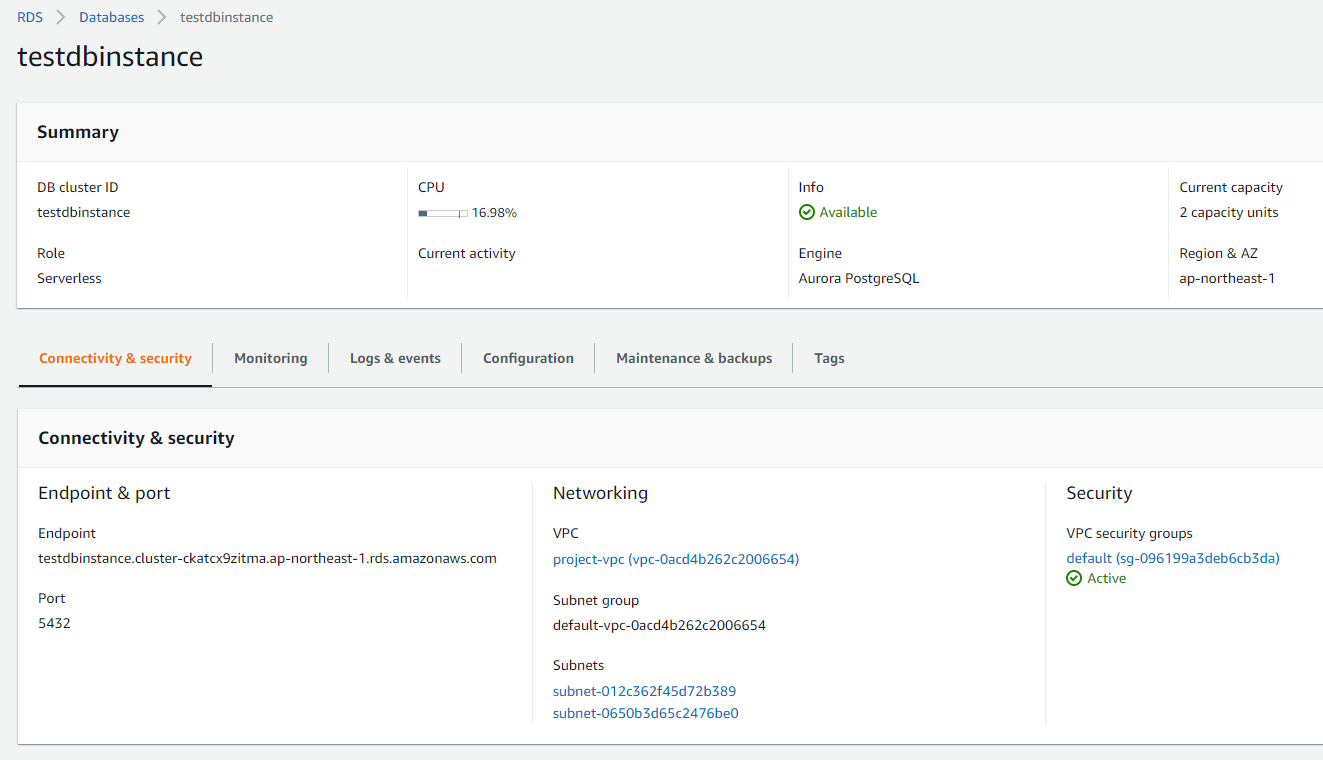
参考:Glueコネクション
セキュリティグループはVPCエンドポイント、RDSと同じSGでした。
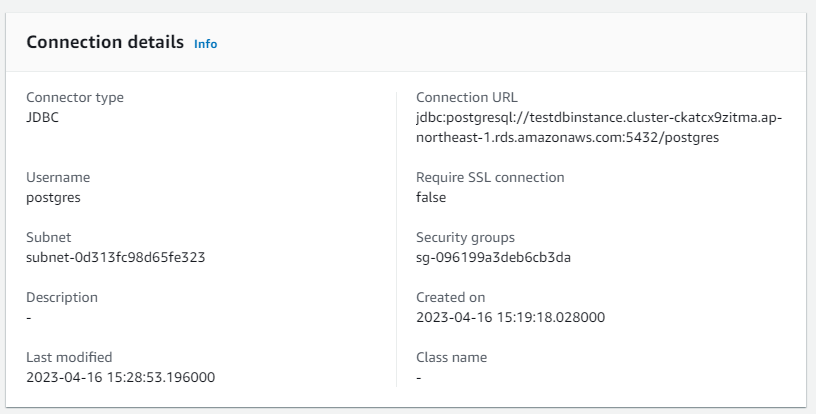
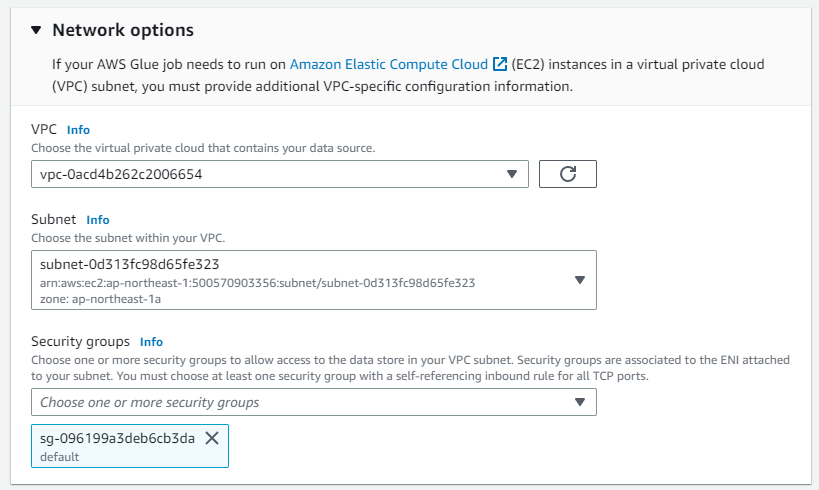

セキュリティグループは見直す必要があるかもしれないわね
S3エンドポイント、Glueエンドポイントの必要性も確認したいわ

そうだね。今後のハンズオンで紐解けなければ、どこかのタイミングで確認してみるよ


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.4) 前回のハンズオンの続きです。 […]