
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回は「Glueデータカタログのその他機能」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue Workflow
- Advanced Topics
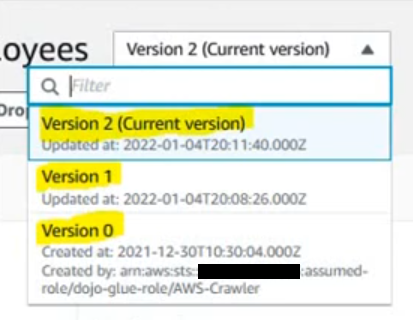
Glueテーブルのスキーマバージョン
- Glueデータカタログ内のテーブルのスキーマの変更履歴を表すバージョン番号
- スキーマが更新されるたびに新たなバージョンが出来る
- 2つのバージョンのスキーマを比較できる
引用元:https://www.youtube-nocookie.com/embed/WUojHQTyTaY
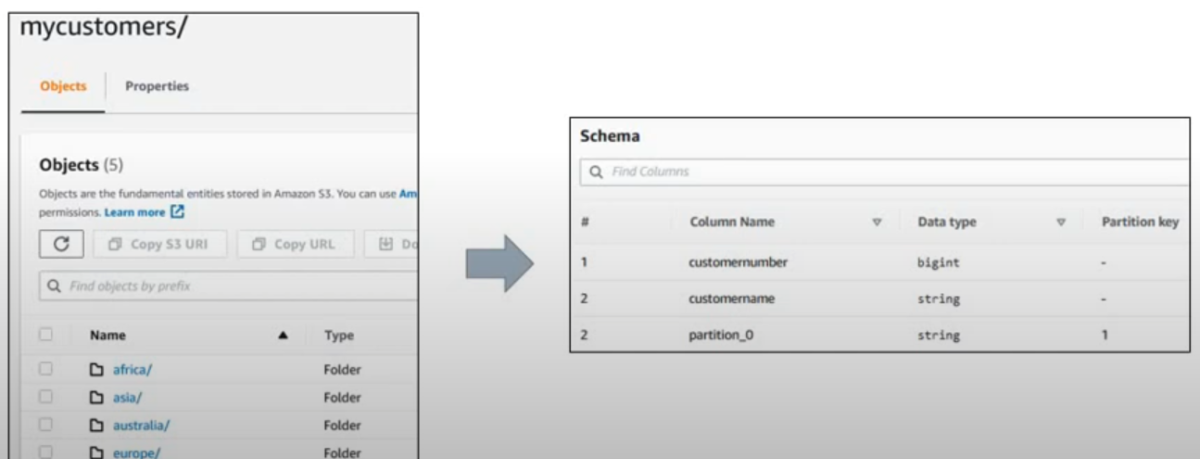
データのパーティショニング
- Glueパーティションは、全体的にデータ転送と処理を削減し、クエリの処理時間を短縮するために使用される
- Glueクローラーはデータ内のパーティションを自動的に識別できる
- 日時(年、月)や地域などで分割
アップロードしたデータをS3バケットに保存する際、例えば地域や日時に基づいてフォルダを分割(パーティションニング)しておくと、クローラーはその分割を自動で認識します。
引用元:https://www.youtube-nocookie.com/embed/WUojHQTyTaY
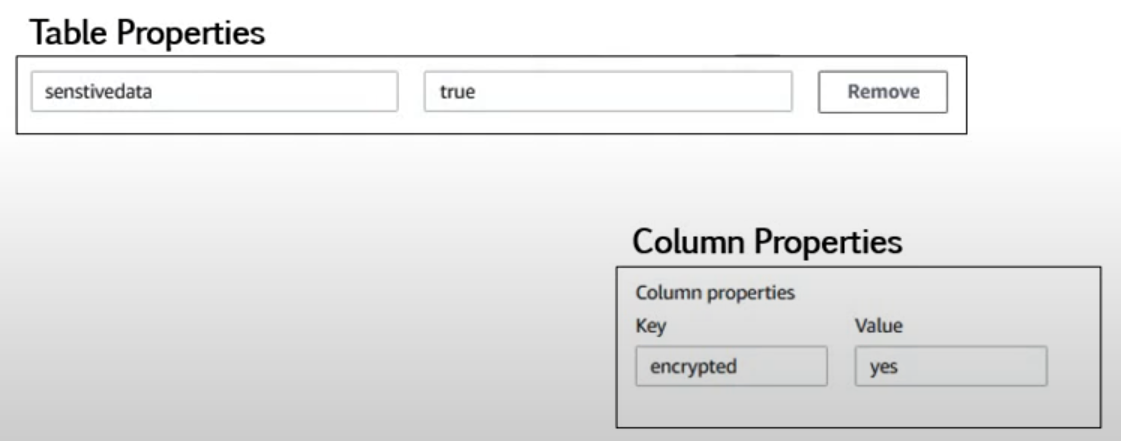
テーブルプロパティ、列プロパティ
- テーブルレベル、列レベルでキーバリュー形式のプロパティを保持できる
- それらはテーブルや列の情報として使われたり、それらを使って特定の決定を下すカスタムロジックの実装に使用する
引用元:https://www.youtube-nocookie.com/embed/WUojHQTyTaY
ハンズオン
今回の内容です。
- Glueデータカタログのスキーマ更新、スキーマバージョン比較
- S3バケットのパーティションをGlueクローラーが自動的に識別し、データカタログに取り込む
前回のハンズオンで作成したGlueテーブルのスキーマ
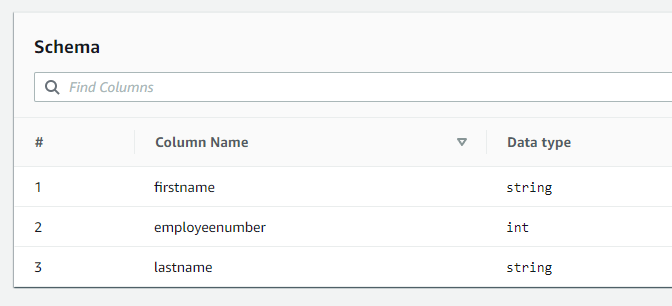
まず、このテーブルのスキーマを変更してGlueクローラーを再度実行します。
そして、スキーマの変更をクローラーが検知するかを確認します。
今回、提供された資材の「5_Glue_Data_Catalog_Revisted」を使います。
[RDS] テーブルスキーマ変更
クエリエディタにて「RDS_Table_Data_Update_Script.sql」を実行します。
![[RDS] テーブルスキーマ変更](https://techuplabo.blog/wp-content/uploads/2023/04/image-224.png)
![[RDS] テーブルスキーマ変更2](https://techuplabo.blog/wp-content/uploads/2023/04/image-225.png)
![[RDS] テーブルスキーマ変更3](https://techuplabo.blog/wp-content/uploads/2023/04/image-226.png)
ALTER文実行により、createdonカラムを追加しました。
続いて前回作成したGlueクローラーを再度実行して、Glueスキーマの変更とカタログテーブルへ取り込みを行います。
[Glue] クローラー再実行
![[Glue] クローラー再実行1](https://techuplabo.blog/wp-content/uploads/2023/04/image-227.png)
![[Glue] クローラー再実行2](https://techuplabo.blog/wp-content/uploads/2023/04/image-228.png)
終わりました。
![[Glue] クローラー再実行3](https://techuplabo.blog/wp-content/uploads/2023/04/image-229.png)
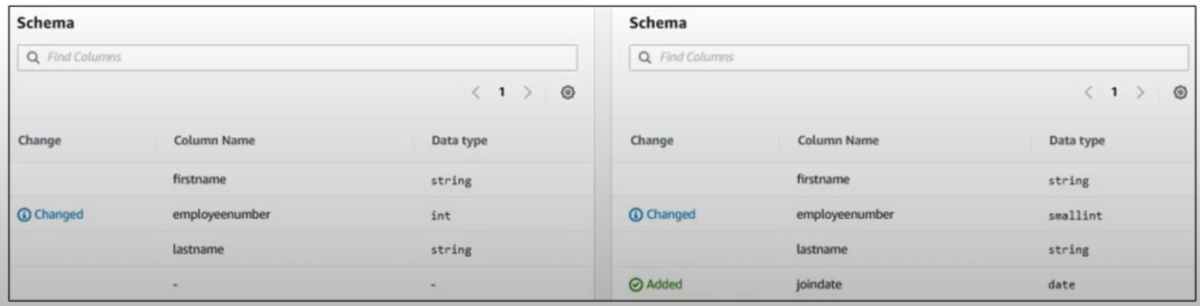
Glueスキーマを見てみると、createdonカラムが追加されてVersion 1 になっています。
![[Glue] クローラー再実行4](https://techuplabo.blog/wp-content/uploads/2023/04/image-230.png)
Version0と1を並べて比較してみます。
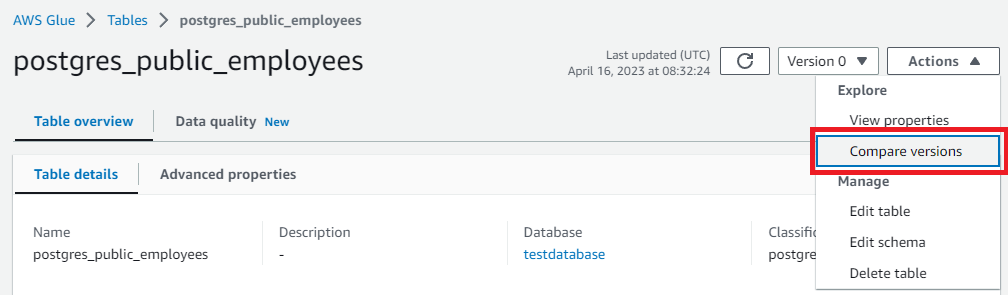
![[Glue] クローラー再実行5](https://techuplabo.blog/wp-content/uploads/2023/04/image-232.png)

変更点がわかりやすいね!
次は、パーティショニングがどのように機能するのか学習します。
[S3] ordersフォルダをアップロード
はじめに提供資材を確認します。
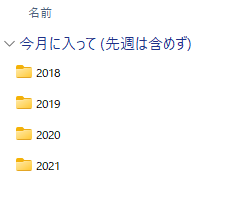

ordersフォルダー配下に年ごとのフォルダがあり、各年フォルダにorders.csvが入っています。
つまり、年でパーティショニングされているということです。
ordersフォルダをS3にアップロードし、クローラーでカタログ化します。
パーティションを認識できるでしょうか?
前回作成したS3バケットにordersフォルダをアップロードします。
![[S3] ordersフォルダをアップロード1](https://techuplabo.blog/wp-content/uploads/2023/04/image-236.png)
![[S3] ordersフォルダをアップロード2](https://techuplabo.blog/wp-content/uploads/2023/04/image-237.png)
![[S3] ordersフォルダをアップロード3](https://techuplabo.blog/wp-content/uploads/2023/04/image-239.png)
ordersフォルダをアップロードできました。
![[S3] ordersフォルダをアップロード4](https://techuplabo.blog/wp-content/uploads/2023/04/image-240.png)
![[S3] ordersフォルダをアップロード5](https://techuplabo.blog/wp-content/uploads/2023/04/image-241.png)
[Glue] ordersフォルダーをカタログ化するクローラーを作成
![[Glue] クローラー作成1](https://techuplabo.blog/wp-content/uploads/2023/04/image-242.png)
![[Glue] クローラー作成2](https://techuplabo.blog/wp-content/uploads/2023/04/image-243.png)
![[Glue] クローラー作成3](https://techuplabo.blog/wp-content/uploads/2023/04/image-244.png)
![[Glue] クローラー作成4](https://techuplabo.blog/wp-content/uploads/2023/04/image-245.png)
![[Glue] クローラー作成5](https://techuplabo.blog/wp-content/uploads/2023/04/image-246.png)
今回はS3なので、接続コネクション(Network connection)を指定する必要はありません。
![[Glue] クローラー作成6](https://techuplabo.blog/wp-content/uploads/2023/04/image-248.png)
![[Glue] クローラー作成7](https://techuplabo.blog/wp-content/uploads/2023/04/image-249.png)
![[Glue] クローラー作成8](https://techuplabo.blog/wp-content/uploads/2023/04/image-250.png)
s3orderscrawlerを追加できました。
![[Glue] クローラー作成9](https://techuplabo.blog/wp-content/uploads/2023/04/image-251.png)
[IAM] ポリシー追加
クローラーにアタッチしたロールを確認します。
![[IAM] ポリシー追加1](https://techuplabo.blog/wp-content/uploads/2023/04/image-254.png)
このポリシーを見ると「特定の名前で始まるバケット」もしくは「特定の名前を含むバケット」になっているため、今回カタログ化対象のバケット(ここではtest-glue-lake-0409)にアクセスすることが出来ません。
![[IAM] ポリシー追加2](https://techuplabo.blog/wp-content/uploads/2023/04/image-255.png)
インラインポリシーを追加します。
![[IAM] ポリシー追加3](https://techuplabo.blog/wp-content/uploads/2023/04/image-256.png)
提供資材「crawler_inline_policy.json」をペーストします。
このとき、バケット名を自分のバケット名に変更しておきます。
![[IAM] ポリシー追加4](https://techuplabo.blog/wp-content/uploads/2023/04/image-257.png)
![[IAM] ポリシー追加5](https://techuplabo.blog/wp-content/uploads/2023/04/image-258.png)
インラインポリシーを追加できました。
これで、S3クローラーは当該バケットにアクセスできるパーミッションを取得しました。
![[IAM] ポリシー追加6](https://techuplabo.blog/wp-content/uploads/2023/04/image-276.png)
[Glue] S3クローラー実行
s3orderscrawlerを実行します。
完了後、Glueカタログにordersテーブルが追加されていました。
年フォルダでパーティションが適用されていることもわかります。
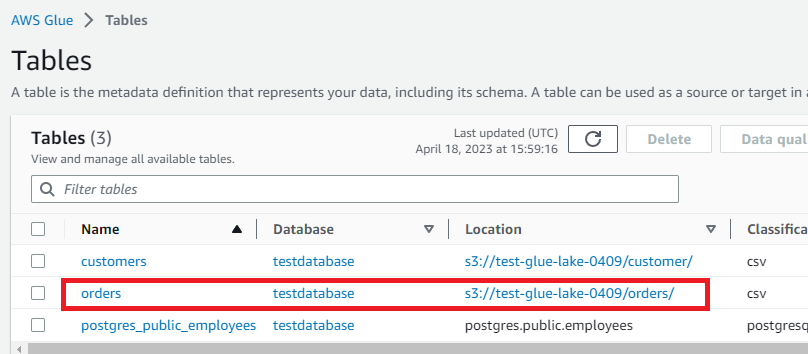
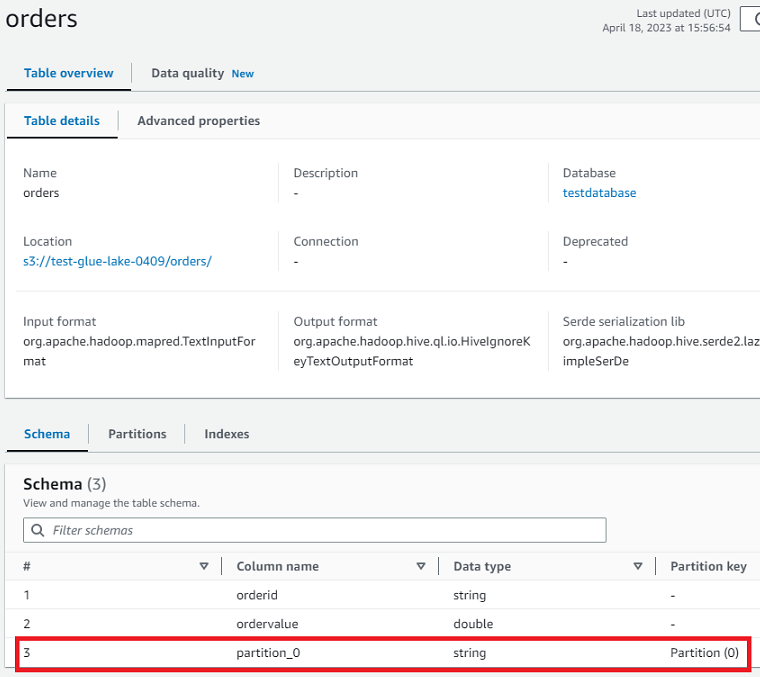
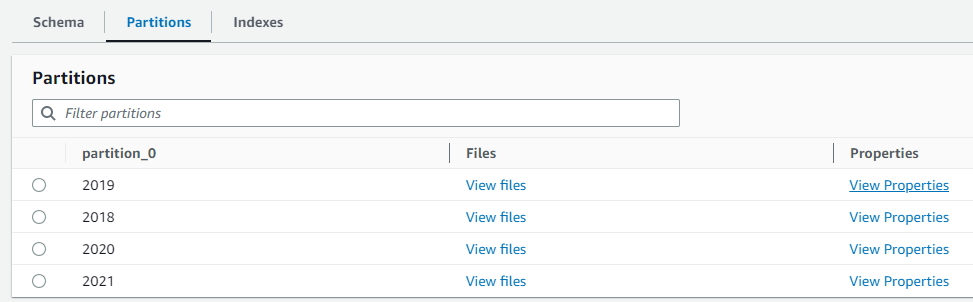
パーティションを追加することで、データが増加してもクエリのパフォーマンスを向上することができます。
[Lake Formation]テーブルプロパティ、列プロパティ
テーブルプロパティを追加してみます。
![[Lake Formation]テーブルプロパティ、列プロパティ1](https://techuplabo.blog/wp-content/uploads/2023/04/image-271.png)
![[Lake Formation]テーブルプロパティ、列プロパティ2](https://techuplabo.blog/wp-content/uploads/2023/04/image-272.png)
続いて列プロパティの追加です。
![[Lake Formation]テーブルプロパティ、列プロパティ3](https://techuplabo.blog/wp-content/uploads/2023/04/image-273.png)
![[Lake Formation]テーブルプロパティ、列プロパティ4](https://techuplabo.blog/wp-content/uploads/2023/04/image-274.png)
![[Lake Formation]テーブルプロパティ、列プロパティ5](https://techuplabo.blog/wp-content/uploads/2023/04/image-275.png)
追加したテーブルプロパティや列プロパティは、ビジネスロジックやカタログ内のデータ処理で利用することが出来ます。
おわりに
今回は以下を学習しました。
- Glueデータカタログのスキーマ更新、スキーマバージョン比較
- S3バケットのパーティションをGlueクローラーが自動的に識別し、データカタログに取り込む
- データカタログのテーブルプロパティ、列プロパティの追加
S3クローラーのIAMロールにインラインポリシーを追加しましたが、実は追加する前にクローラーを実行してみました。
想定ではクローラーが失敗するはずだったのですが、エラーなく終了しました。
Glueにordersテーブルは存在しておらず、ログも特筆すべきものは出ていませんでした。
今後またGlueクローラーでS3バケットをデータカタログに取り込む機会があれば、今回のことを思い出したいと思います。


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.5) 前回のハンズオンの続きです。 […]