
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回は「GlueジョブとGlue Studio」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue Workflow
- Advanced Topics
Glueジョブとは
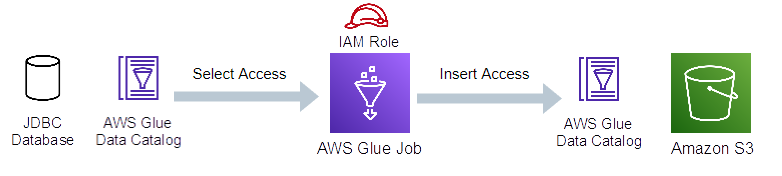
Glueジョブは、あるデータストアから別のデータストアにデータを移動するための抽出、変換、読み込み (ETL)のビジネス ロジックです。
サーバレスなので、インフラを特別プロビジョニングする必要はなく、ジョブを構成して実行するだけです。
Glueジョブの種類
Glueでは、主に3種類のジョブを作成できます。

引用元:https://www.youtube-nocookie.com/embed/QQb_HOmn3MU
- Apache Sparkプラットフォームを使用してジョブを実行
- SparkストリーミングジョブやKinesisなどのサービスのジョブを作成して、ストリーミングデータを処理することもできる。例えばソーシャルメディアプラットフォームや、IoTプラットフォームからストリーミングデータを取得して変換、ロードする
- PythonなどでシェルスクリプトでGlueジョブを作成することもできる
同時実行数、外部ライブラリ
Glueジョブは並列、同時実行を構成することが出来ます。
また、S3バケットに格納した外部ライブラリを使って独自コードをジョブに持ち込むことが出来ます。
Glueジョブのブックマーク
一言で言えば差分更新のような機能です。
Glueは、ジョブのブックマークを使用して、以前のETLジョブ実行によって処理されたデータを追跡します。
これにより、データの再処理を防ぐことができます。
JDBCの種類のデータソースを使用している場合であれば、データの再処理を回避するために使用できます。データストアの場合は主キーや列の組合せを使用してジョブブックマークを定義できるので、それらの組合せが新しいデータを取得しない限り、処理したデータの再処理は行いません。
S3の場合は、列の組合せを使用してジョブのブックマークを定義するか、オブジェクトの変更タイムスタンプを使用することもできます。
ジョブのブックマークは、Glueジョブの非常に重要な機能です。
Glue Studio
Glue Studioは、ETL操作のためのGlueジョブを作成、実行、そして監視するためのグラフィカルインターフェースです。
開発手法には以下の2つがあります。
- ノードブロックをドラッグ&ドロップ
- SparkまたはPythonを使用してコードを書く
Glue Studioでドラッグ&ドロップするノードアイコンには以下があります。
(少し古いかもしれません)
Extract
Transform
Spigotとは「変換中に指定した場所にサンプルレコードを書き込み」のことです。

Spigot(スピゴット)って何?

Glueジョブで実行された変換を確認しやすくなるように、サンプルレコードを指定した送信先に書き込むことよ。
ハンズオン
今回の内容です。
- Glueスタジオで、RDSのデータをS3にデータを書き込むGlueジョブを作成
現在の状態
S3には以下のバケット、その配下にはフォルダがいくつか存在します。
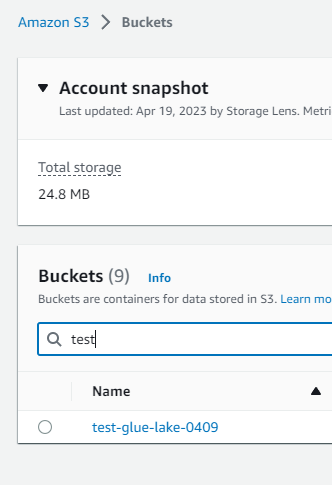
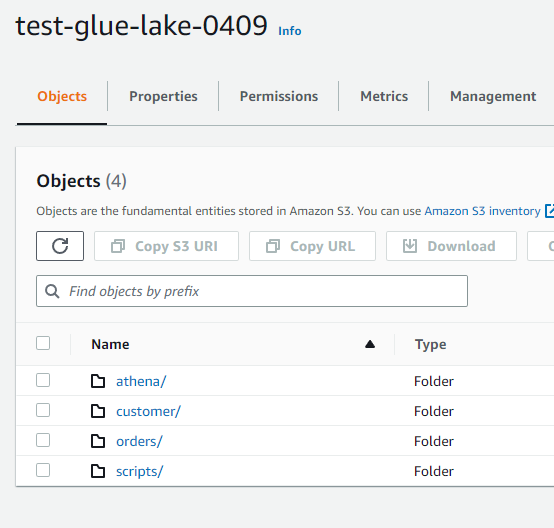
Lake Formationを見てみます。これまでのハンズオンで以下の状態です。
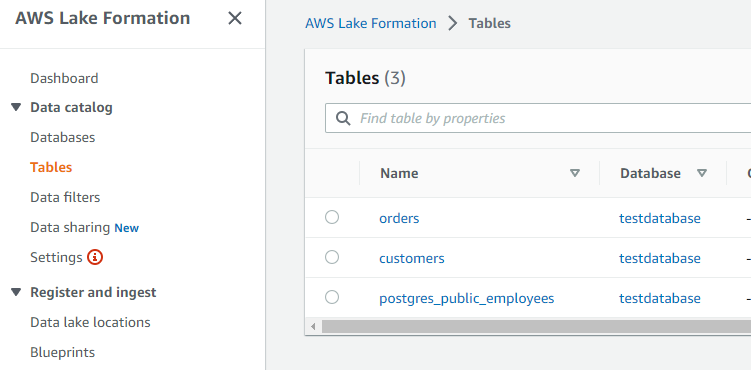
orders, customersテーブルはS3。posrgres_public_employeesテーブルはPostgreSQLデータベースです。
これからやろうとしていることは、GlueジョブでRDSのデータをS3に書き込むことです。
[IAM] Glueジョブ用のロール作成
![[IAM] Glueジョブ用のロール作成1](https://techuplabo.blog/wp-content/uploads/2023/04/image-282.png)
![[IAM] Glueジョブ用のロール作成2](https://techuplabo.blog/wp-content/uploads/2023/04/image-283.png)
![[IAM] Glueジョブ用のロール作成3](https://techuplabo.blog/wp-content/uploads/2023/04/image-284.png)
![[IAM] Glueジョブ用のロール作成4](https://techuplabo.blog/wp-content/uploads/2023/04/image-285.png)
test_job_roleが出来たら、ポリシーを追加します。
![[IAM] Glueジョブ用のロール作成5](https://techuplabo.blog/wp-content/uploads/2023/04/image-286.png)
なぜなら、このロールのポリシーにS3アクセス権限がありますが、バケット名が「aws-glue-から始まる」「aws-glue-を含む」バケットにしかアクセスできないためです。
![[IAM] Glueジョブ用のロール作成6](https://techuplabo.blog/wp-content/uploads/2023/04/image-287.png)
提供された資材のこれを使います。
![[IAM] Glueジョブ用のロール作成7](https://techuplabo.blog/wp-content/uploads/2023/04/image-288.png)
![[IAM] Glueジョブ用のロール作成8](https://techuplabo.blog/wp-content/uploads/2023/04/image-290.png)
![[IAM] Glueジョブ用のロール作成9](https://techuplabo.blog/wp-content/uploads/2023/04/image-292.png)
インラインポリシーのS3バケット名は、自分用に変更する必要があります(ここではtest-glue-lake-0409)。
![[IAM] Glueジョブ用のロール作成10](https://techuplabo.blog/wp-content/uploads/2023/04/image-295.png)
![[IAM] Glueジョブ用のロール作成11](https://techuplabo.blog/wp-content/uploads/2023/04/image-296.png)
インラインポリシーを追加できました。
![[IAM] Glueジョブ用のロール作成12](https://techuplabo.blog/wp-content/uploads/2023/04/image-297.png)
これで、Lake Formationで使用するこのロールは、S3バケットに対するパーミッションを与えられました。
[Lake Formation] 作成したロールにS3へのパーミッション付与
作成したIAMロールにS3バケットへのパーミッションを与えましたが、Lake Formationにはまだパーミッションを与えていません。これを与える必要があります。
RDSのemployeesテーブルへ付与している、現在のパーミッションを確認します。
![[Lake Formation] 作成したロールにS3へのパーミッション付与1](https://techuplabo.blog/wp-content/uploads/2023/04/image-300.png)
![[Lake Formation] 作成したロールにS3へのパーミッション付与2](https://techuplabo.blog/wp-content/uploads/2023/04/image-299.png)
test_job_roleはまだパーミッションを持っていないことがわかります。右上のGrantボタンから付与します。
![[Lake Formation] 作成したロールにS3へのパーミッション付与3](https://techuplabo.blog/wp-content/uploads/2023/04/image-303.png)
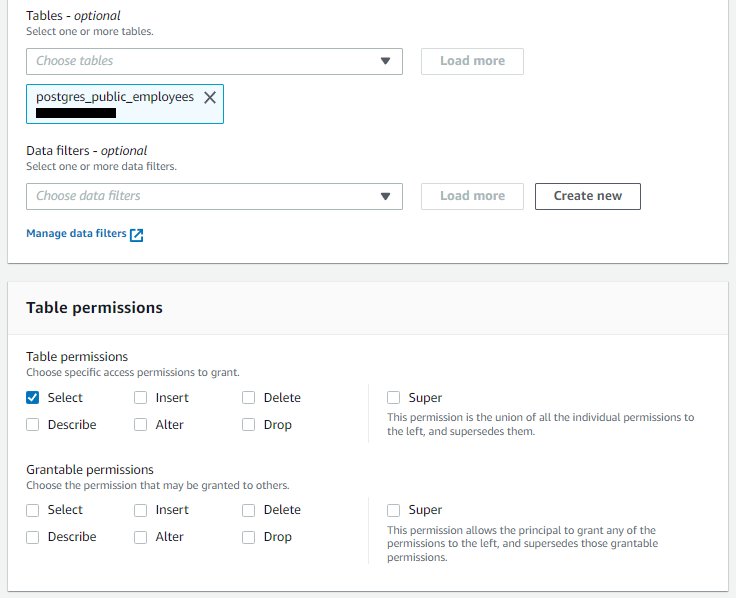
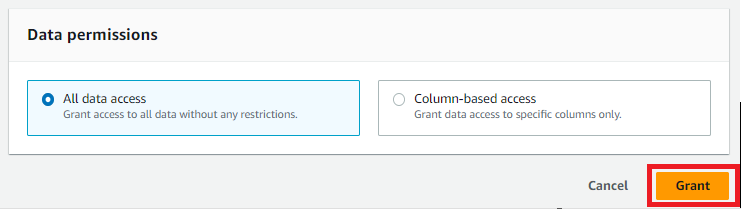
これでLake Formationに対し、test_job_roleによるRDS/employeesテーブルへのSELECT権限を付与することができました。
![[Lake Formation] 作成したロールにS3へのパーミッション付与4](https://techuplabo.blog/wp-content/uploads/2023/04/image-309.png)
[S3] employeesテーブルのデータを書き込むS3バケットを作成
![[S3] employeesテーブルのデータを書き込むS3バケットを作成1](https://techuplabo.blog/wp-content/uploads/2023/04/image-306.png)
ここにemployeesフォルダを作成します。
![[S3] employeesテーブルのデータを書き込むS3バケットを作成2](https://techuplabo.blog/wp-content/uploads/2023/04/image-307.png)
![[S3] employeesテーブルのデータを書き込むS3バケットを作成3](https://techuplabo.blog/wp-content/uploads/2023/04/image-308.png)
以上で準備は整いました。Glueジョブを作りましょう。
[Glue] スタジオでジョブ作成および実行
空白のキャンバスから始めます。
![[Glue] Glueスタジオでジョブ作成1](https://techuplabo.blog/wp-content/uploads/2023/04/image-310.png)
![[Glue] Glueスタジオでジョブ作成2](https://techuplabo.blog/wp-content/uploads/2023/04/image-311.png)
![[Glue] Glueスタジオでジョブ作成3](https://techuplabo.blog/wp-content/uploads/2023/04/image-312.png)
Glueデータカタログのtestdatabaseおよびemployeesテーブルを選択します。
![[Glue] Glueスタジオでジョブ作成4](https://techuplabo.blog/wp-content/uploads/2023/04/image-313.png)
Output schemaを選択し、Transformノードを追加します。
![[Glue] Glueスタジオでジョブ作成5](https://techuplabo.blog/wp-content/uploads/2023/04/image-314.png)
Select Fieldsを選択します。
![[Glue] Glueスタジオでジョブ作成6](https://techuplabo.blog/wp-content/uploads/2023/04/image-315.png)
今回、firstnameとlastnameだけを取得します。
![[Glue] Glueスタジオでジョブ作成7](https://techuplabo.blog/wp-content/uploads/2023/04/image-316.png)
PostgreSQLからはテーブル丸ごと(4カラム丸ごと)取得ですが、このSelect Fields変換でfirstnameとlastnameの取得だけになりました。これが変換(Transform)です。
![[Glue] Glueスタジオでジョブ作成8](https://techuplabo.blog/wp-content/uploads/2023/04/image-318.png)
ここでETLの「E(extract)」と「T(transform)」を行っているのね
続いてS3へ書き込むため、TargetのS3を選択します。
![[Glue] Glueスタジオでジョブ作成](https://techuplabo.blog/wp-content/uploads/2023/04/image-319.png)
設定を以下のとおり行います。Glueデータカタログとしてのemployeesテーブルを作る設定を忘れずに。
![[Glue] Glueスタジオでジョブ作成10](https://techuplabo.blog/wp-content/uploads/2023/04/image-320.png)
これでETLの「L(Load)」も完成ね
Scriptタブを選択すると、ソースコードを確認できます。
![[Glue] Glueスタジオでジョブ作成11](https://techuplabo.blog/wp-content/uploads/2023/04/image-321.png)
Job detailsタブでジョブ名などを設定します。
![[Glue] Glueスタジオでジョブ作成12](https://techuplabo.blog/wp-content/uploads/2023/04/image-322.png)
![[Glue] Glueスタジオでジョブ作成13](https://techuplabo.blog/wp-content/uploads/2023/04/image-323.png)
保存し、実行します。
![[Glue] Glueスタジオでジョブ作成14](https://techuplabo.blog/wp-content/uploads/2023/04/image-324.png)
![[Glue] Glueスタジオでジョブ作成15](https://techuplabo.blog/wp-content/uploads/2023/04/image-325.png)
実行中(Running)であるのがわかります。
![[Glue] Glueスタジオでジョブ作成16](https://techuplabo.blog/wp-content/uploads/2023/04/image-326.png)
正常終了しました。
![[Glue] Glueスタジオでジョブ作成17](https://techuplabo.blog/wp-content/uploads/2023/04/image-327.png)
Job run monitoringを見ると、実行状況やログなどを確認することが出来ます。
![[Glue] Glueスタジオでジョブ作成18](https://techuplabo.blog/wp-content/uploads/2023/04/image-328.png)
[Lake Formation] データカタログの確認
ジョブの結果を見てみます。Lake Formationのテーブルにemployeesが追加されています。
![[Lake Formation] データカタログの確認1](https://techuplabo.blog/wp-content/uploads/2023/04/image-329.png)
想定通り、csv形式でfirstnameとlastnameだけのスキーマで作成されたことを確認できました。
![[Lake Formation] データカタログの確認2](https://techuplabo.blog/wp-content/uploads/2023/04/image-330.png)
おわりに
Glueジョブでデータカタログを使用し、RDSデータを変換してS3に書き込むことが出来ました。
今回はこれだけですが、GlueジョブのETLはもっと色々なことが出来るそうです。
機会を得てさらに学んでいこうと思います。


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.6) 前回のハンズオンの続きです。 […]