
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回は「データアクセス制御」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue workflow
- Advanced Topics
クローラーやGlueジョブの前に、なぜデータアクセス制御?
Youtubeの冒頭でこう問いかけます。
「クローラーやGlueジョブの前に、なぜデータアクセス制御?」
回答は以下でした。
「クローラーやGlueジョブ、ワークフローを利用するには、データへのアクセス許可が必要。そのためにもデータアクセス制御を理解することはとても重要です。」
データアクセス制御のシナリオ
Glueのクローラーまたはジョブ、ジョブワークフローを使用するには、データに対する特定の権限が必要です。
これらのクローラーまたはジョブに権限がない限り、割り当てられたタスクを実行することはできません。
事前にデータアクセス制御を行うことでタスクを実行することが出来ます。
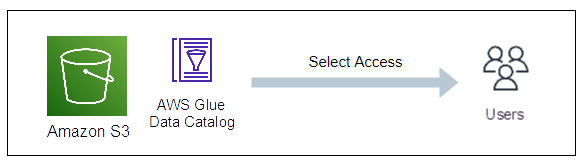
【例1】カタログ化したS3のデータに対してユーザがクエリを実行
ユーザーは、データに対するSelectアクセス許可を必要とします。
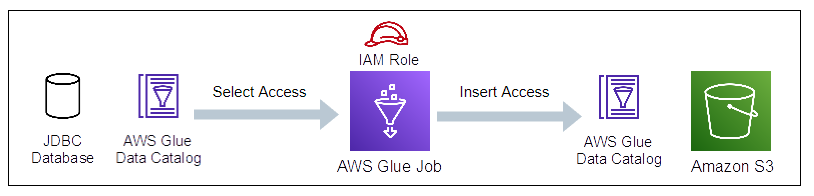
【例2】カタログ化したJDBCエンドポイントからGlueジョブが参照しS3へ書込
Glueジョブは、ソースへのSelectアクセス許可とターゲットへのInsertアクセス許可を必要とします。
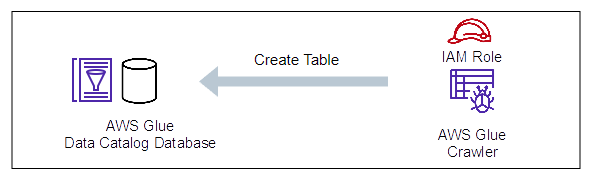
【例3】GlueデータベースにGlueクローラーがテーブルを作成
Glueクローラーは、Glueデータベースへのテーブル作成許可が必要
上記のようなアクセス許可は、AWS Lake Formationを用いて付与します。
データアクセス制御がどのように機能するかを理解しておく必要があります。
Glueデータカタログのデータベースに対する権限タイプ
データベースレベルのパーミッションには以下が存在します。
| Create table | テーブルを作成できるか |
| Alter | データベースを変更できるか |
| Drop | データベースを削除できるか |
| Describe | データベースの情報を記述または取得できるか |
| Super | 上記すべての許可を持つ |
Glueデータカタログのテーブルに対する権限タイプ
テーブルレベルのパーミッションには以下が存在します。
| Select | データを取得できるか |
| Insert | データを登録できるか |
| Delete | データを削除できるか |
| Describe | テーブルの情報を記述または取得できるか |
| Alter | テーブル定義を変更できるか |
| Drop | テーブルを削除できるか |
| Super | 上記すべての許可を持つ |
Glueデータカタログのテーブルに対するデータフィルター
列レベルまたは行レベルで許可を与えることもできます。
これらは以下のように呼ばれ、データフィルターを介して提供されます。
- 列レベルのアクセス(特定の列を含めたり除外したりできる)
- 行レベルのアクセス(特定の行を含めたり除外したりできる)
ハンズオン
今回は以下がポイントです。
- データフィルターを用いて、テーブルデータへの列アクセスおよび行アクセスを制御
- Athenaでクエリを発行して上記アクセス制御を確認
前提
前回作成したデータベースにcustomersテーブルがあり、クエリを発行するとS3の格納したデータを参照することができる状態から始めます。
特に制御をかけていない状態で下記のSELECTクエリを実行すると、customerid、customername、customeremail、territoryを出力します。
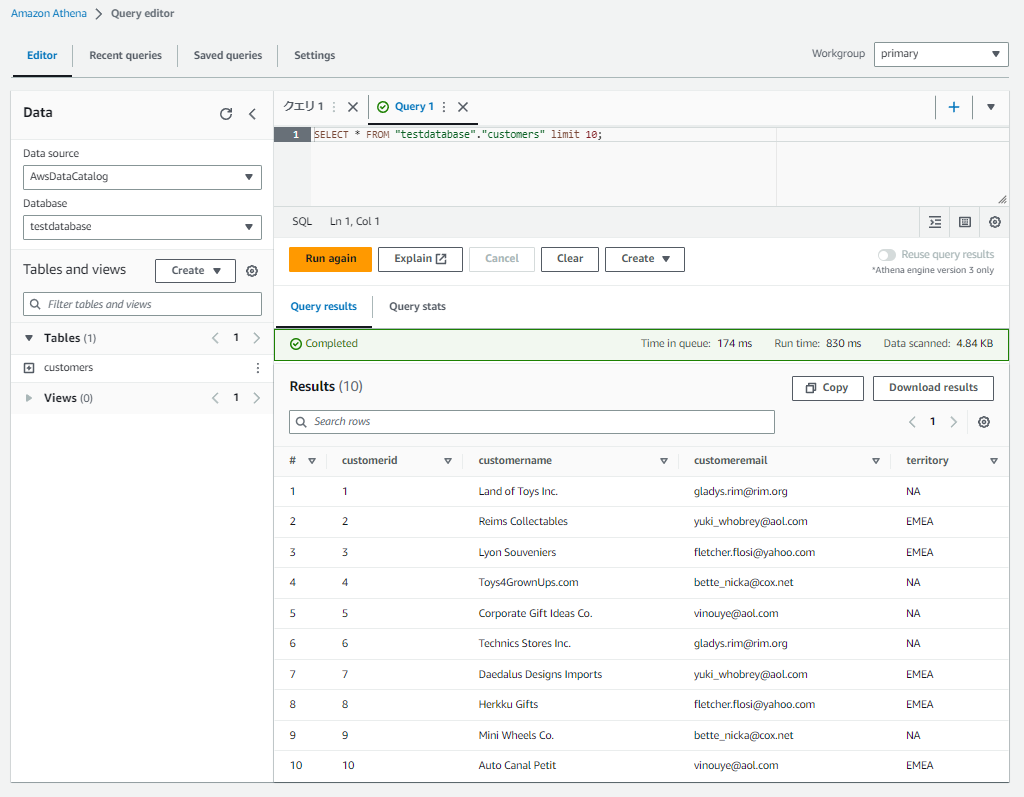
これから、2人のユーザーに異なるデータフィルタ―を割り当て、それぞれが異なる列レベルと行レベルでアクセス制御できることを検証していきます。
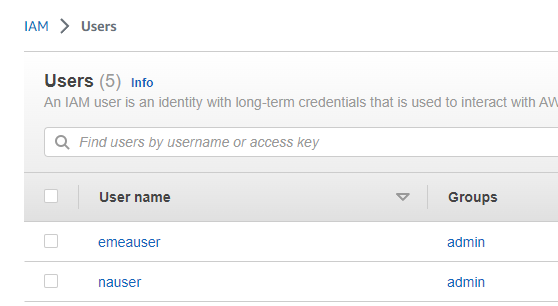
IAMユーザ作成
IAMを開き、2人のユーザーを作成します。
nauser
1人目のユーザー「nauser」を作成
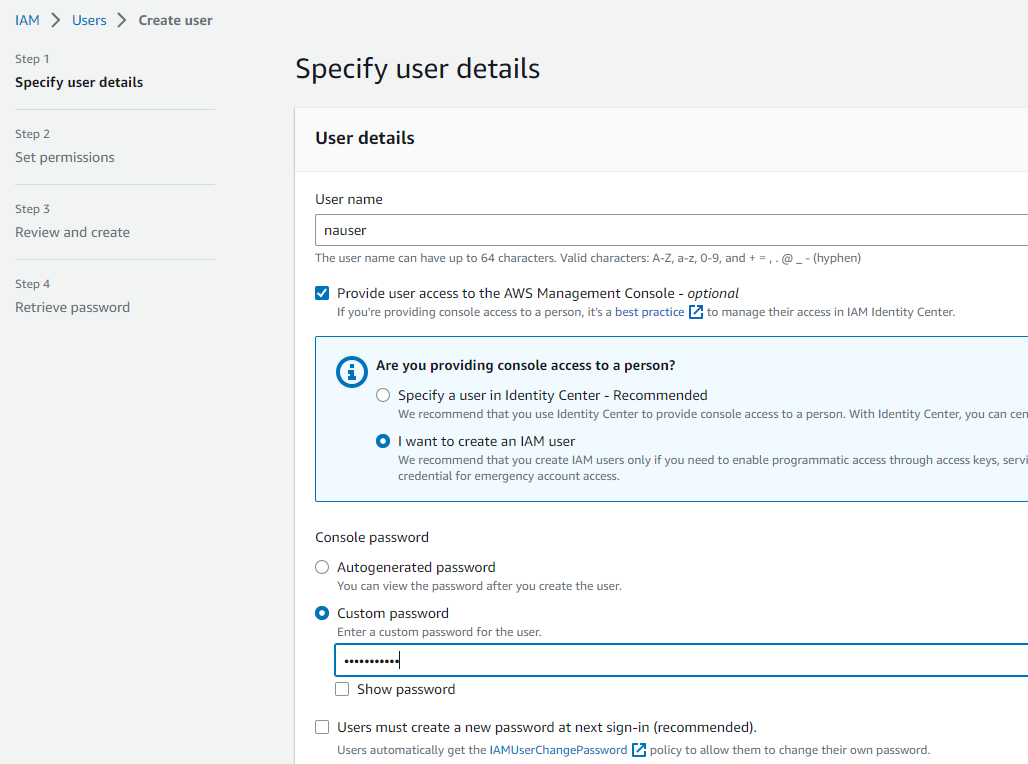
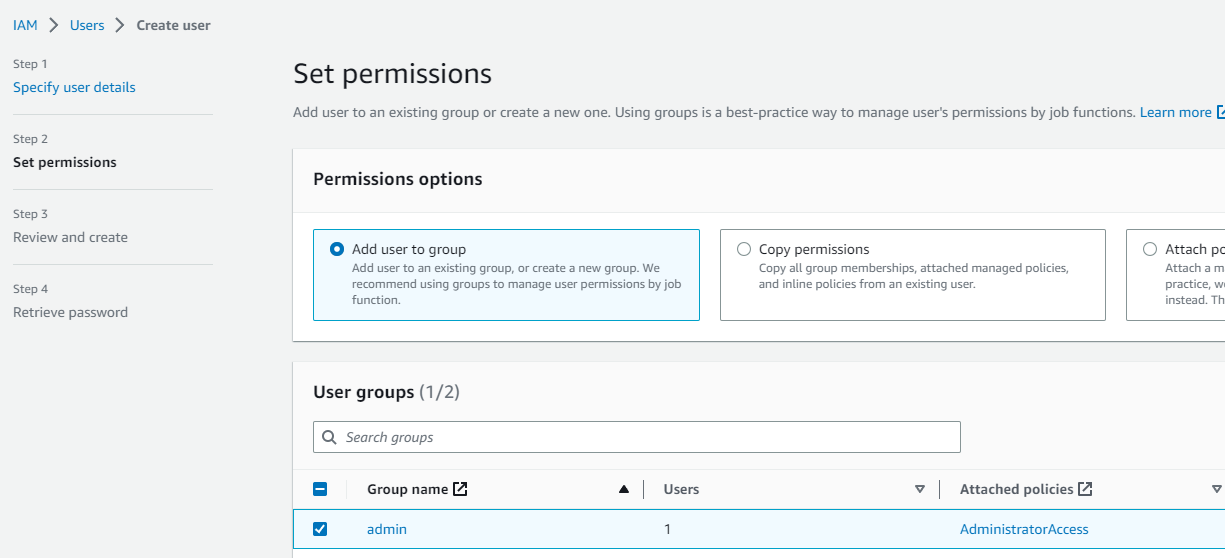
シンプルにするため管理者権限を付与します。
emeauser
もう1人「emeauser」を同様に作成します。
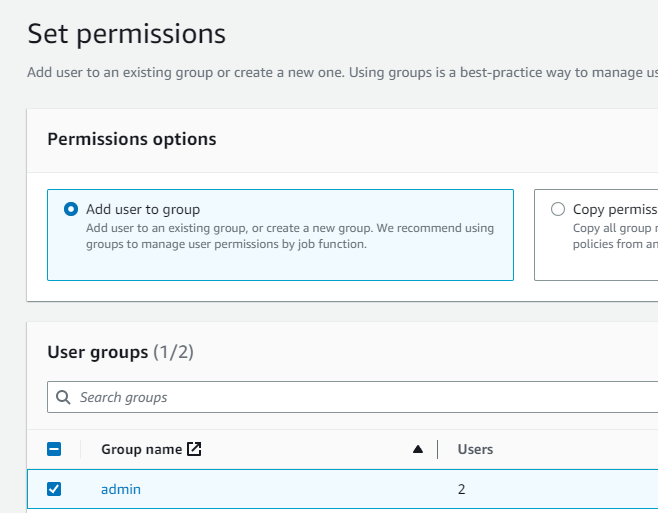
2人のIAMユーザーを作成完了しました。
[Lake Formation] データフィルタ―作成
Lake Formationを表示します。
前回のハンズオンで作成したデータベースとテーブルが存在することがわかります。
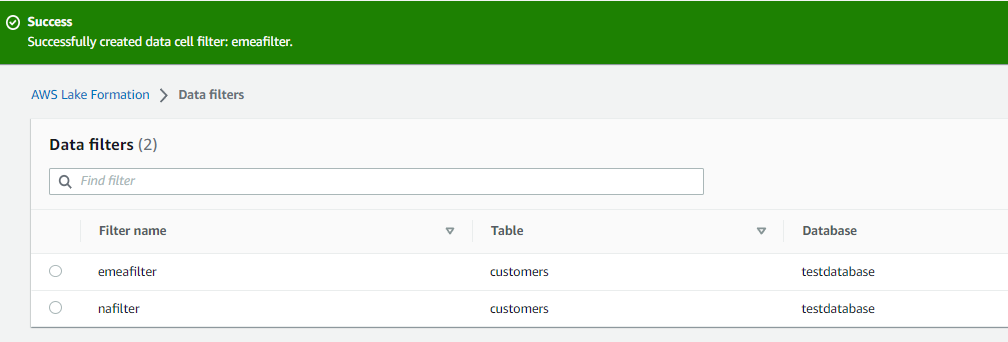
2つの異なるデータフィルタ―を作成します。
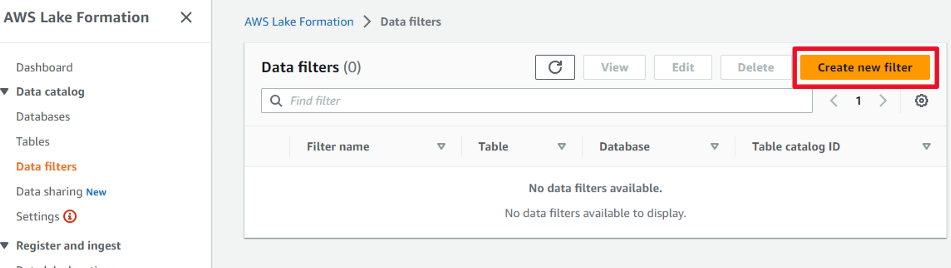
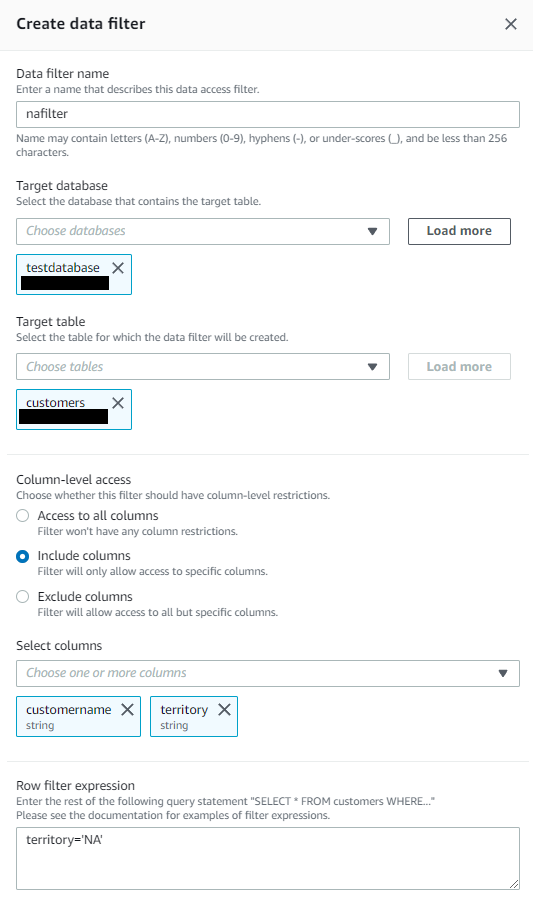
nafilter
1つ目のデータフィルタ―「nafilter」を作成します。
データフィルタ―:nafilter
- 「customername」「territory」の列のみアクセス可(列レベルアクセス)
- 「territoryが’NA’」の行のみアクセス可(行レベルアクセス)
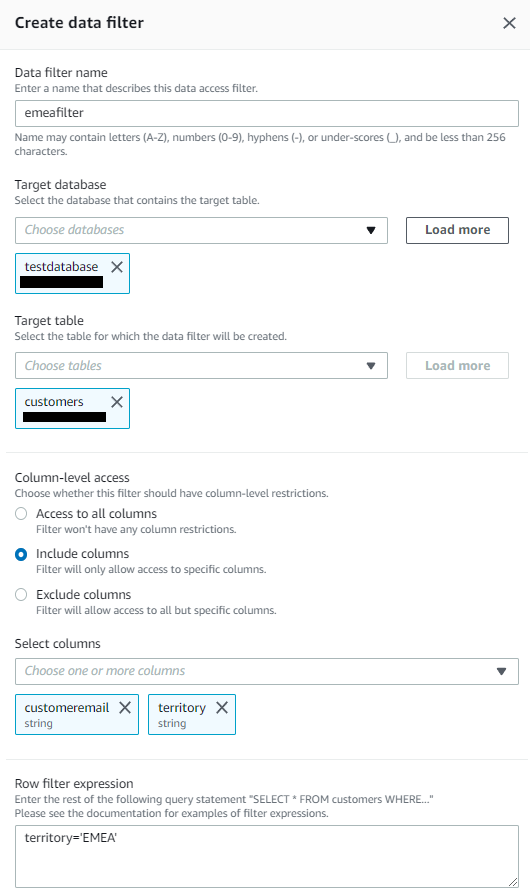
emeafilter
2つ目のデータフィルタ―「emeafilter」を作成します。
データフィルタ―:emeafilter
- 「customeremail」「territory」の列のみアクセス可(列レベルアクセス)
- 「territoryが’EMEA’」の行のみアクセス可(行レベルアクセス)
2つのデータフィルターを作成しました。
[Lake Formation] ユーザーへのデータフィルタ割当て
2人のユーザーnauserとemeaユーザーにデータフィルタを割り当て、アクセスを許可します。
nauserへのデータフィルタ―割当て
nauserには、データフィルタ―nafilterをセットし、Selectを許可します。
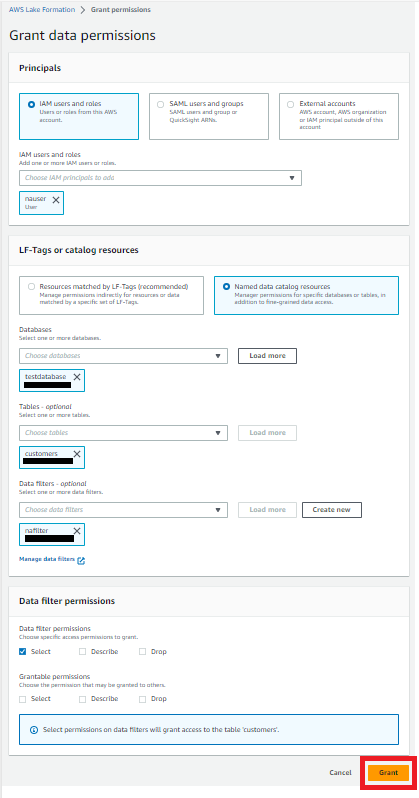
nauserにnafilterの割り当てが完了しました。
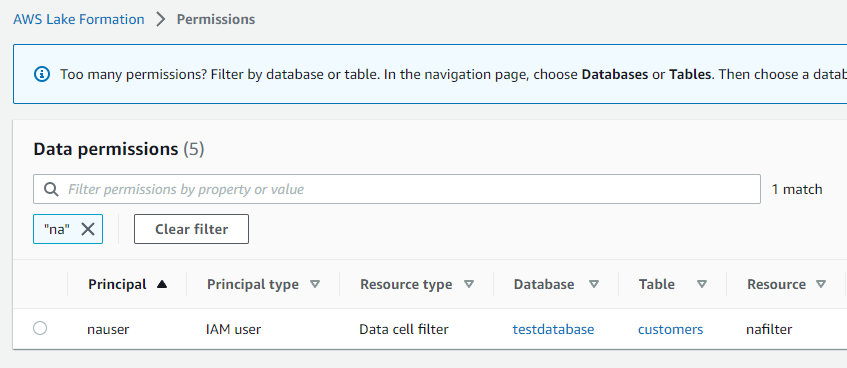
emeauserへのデータフィルタ―割当て
同様の手順で、emeauserにはデータフィルタ―emeafilterをセットし、Selectを許可します。
2人へのデータフィルタ―割当てを完了しました。
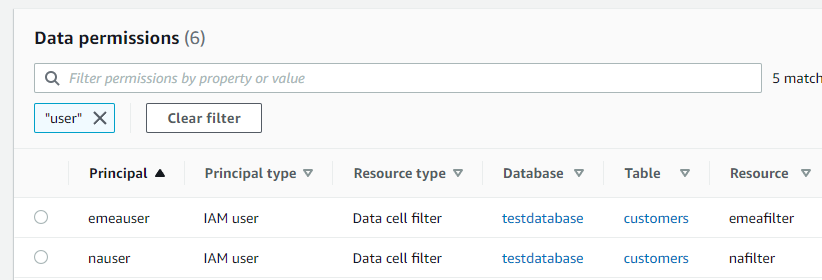
[Athena] ワークグループの作成
ワークグループごとに、クエリ履歴やクエリのスキャン量を変更することができるようです。
例えば部署ごとに分けるといった使い方が出来ます。
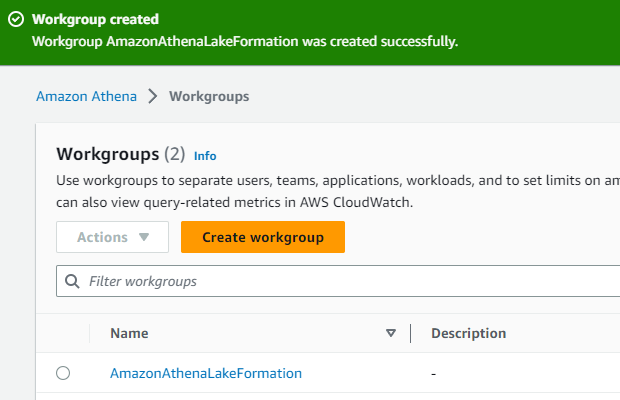
Athenaを表示し「Create workgroup」ボタンを押下します。
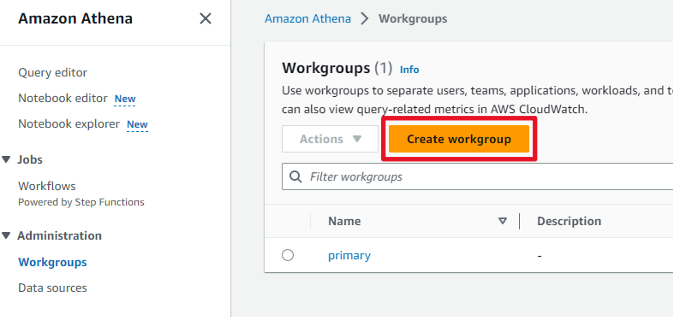
ワークグループ名は「AmazonAthenaLakeFormation」
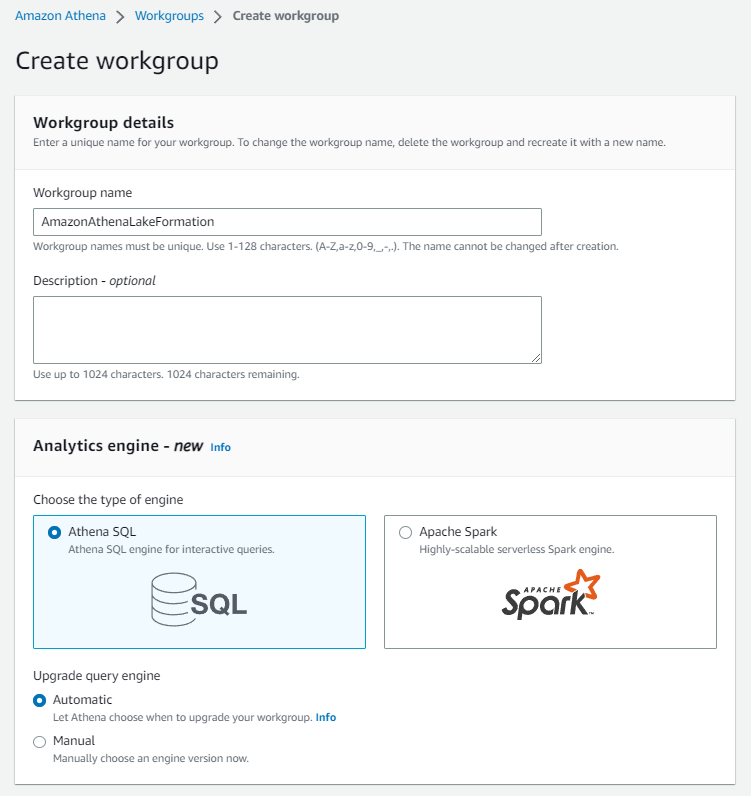
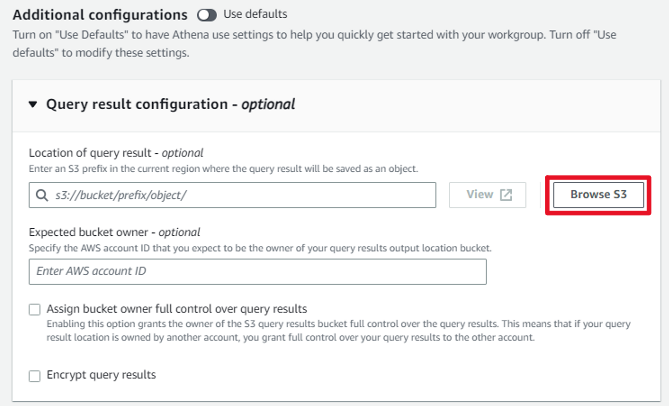
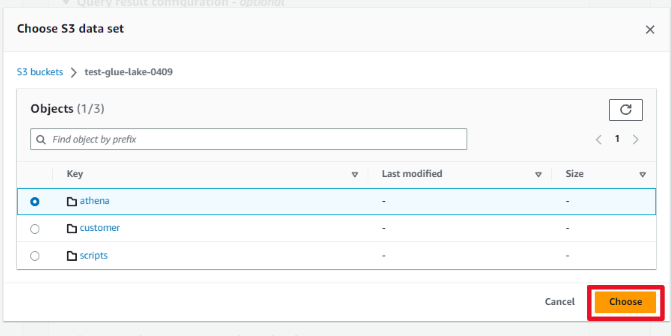
クエリ結果格納先は、前回S3に作成したathenaフォルダをセットします。
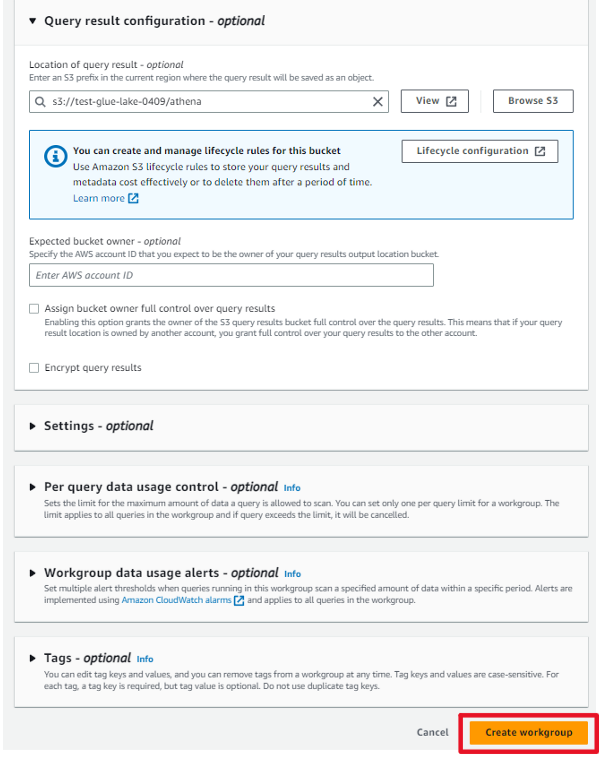
作成完了しました。
[Athena] nauserでクエリ結果を確認
nauserに対してデータフィルタ「nafilter」でアクセス許可が出来ているか確認します。
nauserでコンソールにログインしました。
Athenaを開きます
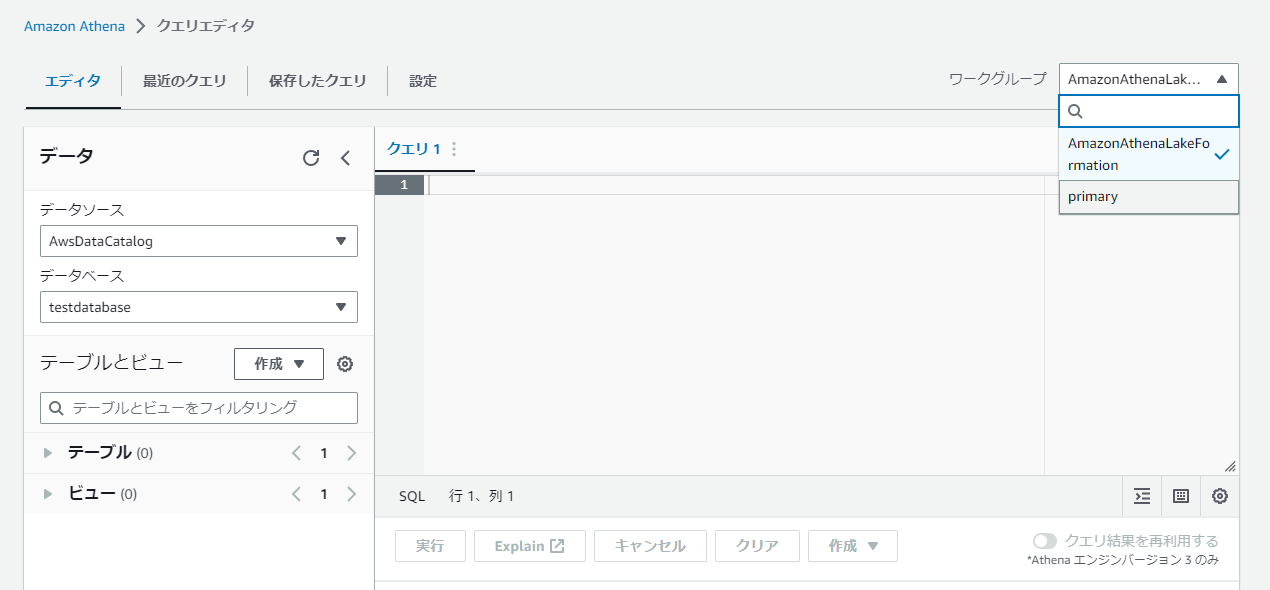
ワークグループを先ほど作成した「AmazonAthenaLakeFormation]に切り替えます。
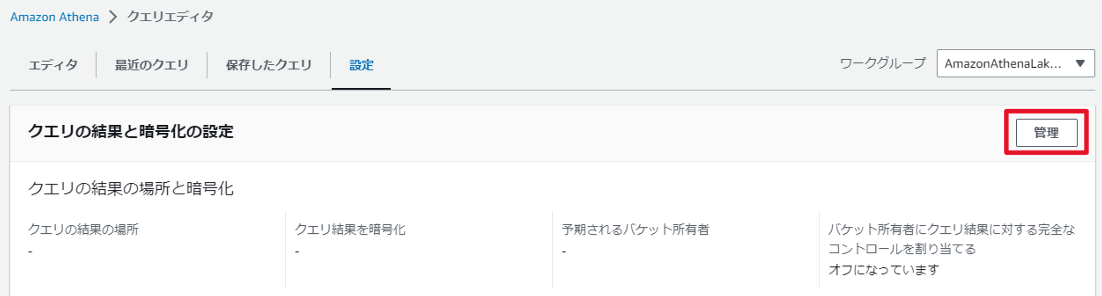
クエリ結果の保存先にS3のathenaフォルダを設定します。
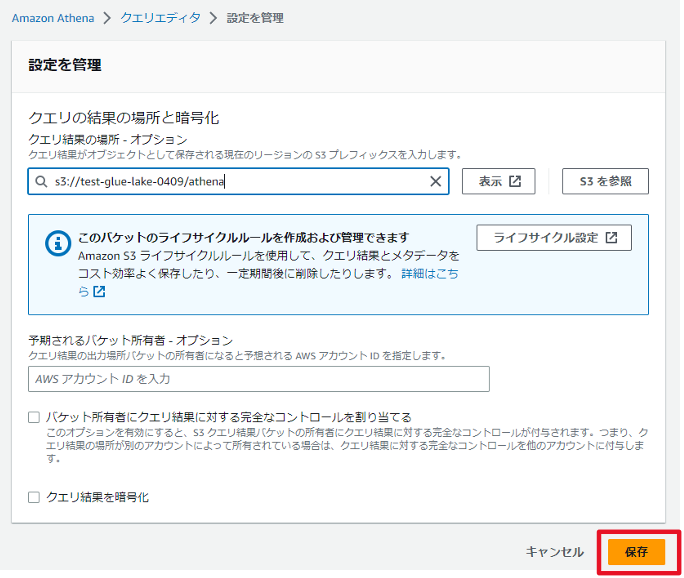
Athenaクエリ結果の保存先は2か所で設定が必要なようです。
・ワークグループ
・クエリエディタ
ようやく準備ができたので、nauserでクエリを実行します。
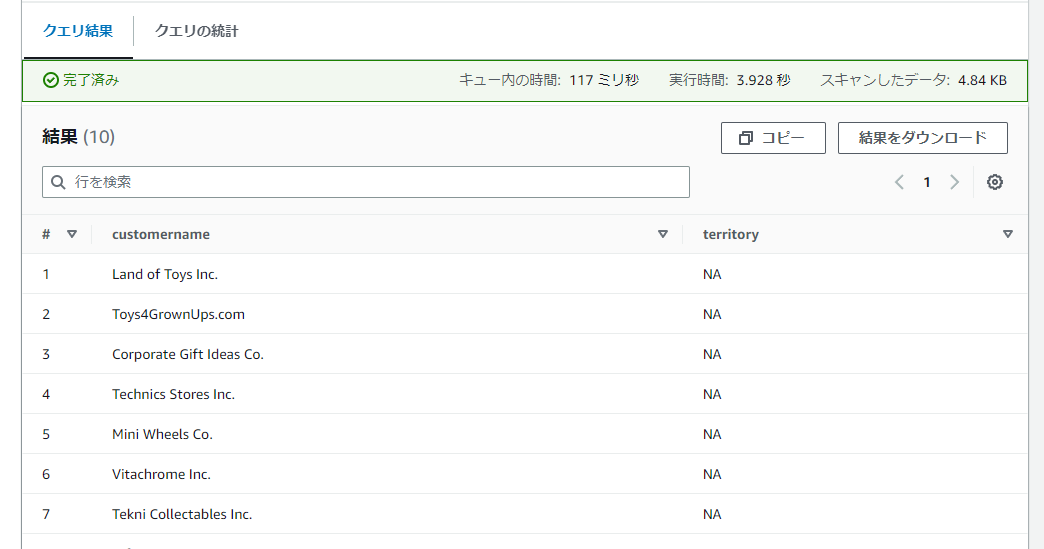
データフィルター「nafilter」の内容でアクセス制御できていることを確認できました。
データフィルタ―:nafilter
- 「customername」「territory」の列のみアクセス可(列レベルアクセス)
- 「territoryが’NA’」の行のみアクセス可(行レベルアクセス)
[Athena] emeauserでクエリ結果を確認
emeauserでログインしなおし、同様の手順でemeauserのアクセス制御ができているかを確認します。
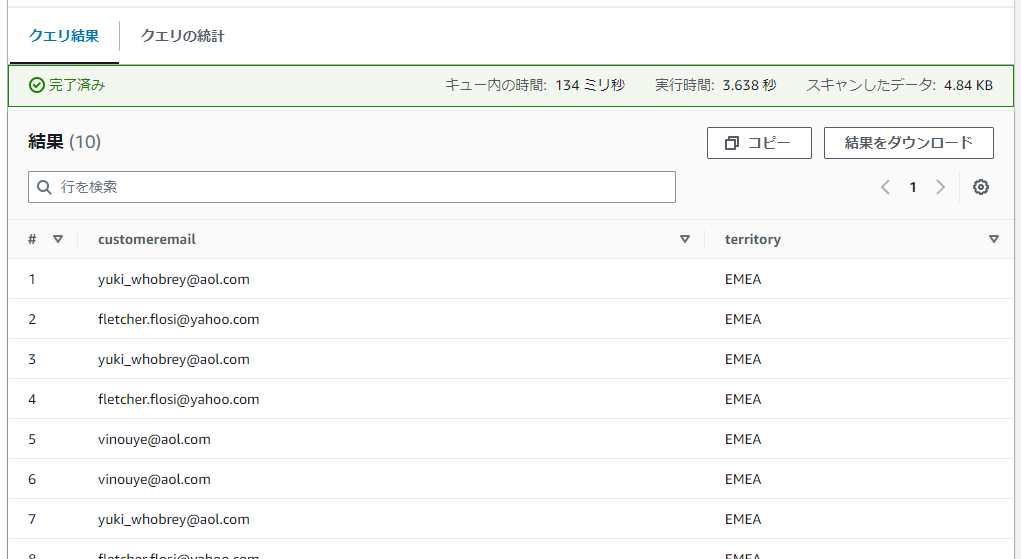
データフィルター「emeafilter」の内容でアクセス制御できていることを確認できました。
データフィルタ―:emeafilter
- 「customeremail」「territory」の列のみアクセス可(列レベルアクセス)
- 「territoryが’EMEA’」の行のみアクセス可(行レベルアクセス)
おわりに
今回は以下の手順で、LakeFormationのよるアクセス制御を学びました。
- IAMユーザを2人追加
- Lake Formationで異なるデータフィルタ(列アクセス+行アクセス)を2つ作成
- Lake Formationで2人のユーザに異なるデータフィルタを割当て
- 2人が同じクエリをAthenaで実行したにも関わらず、異なる結果を得たことを確認(想定どおり)


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.3) 前回のハンズオンの続きです。 […]