
前回のハンズオンの続きです。

データガバナンスにどんなサービスを使い、どのようなことが出来るのか。
以下のYoutubeを参考にさせていただき学習します。
以下の流れで構成されており、今回は「Glueワークフロー」です。
- Glue Data Catalog
- Data Access Control
- Glue Crawler
- Glue Data Catalog Revisited
- Glue Job and Glue Studio
- Glue Workflow
- Advanced Topics
Glueワークフロー
- ジョブとクローラーをオーケストレートすることでETLパイプラインを構築するために利用されます。
- 単一のエンティティとして実行され、いつでもパイプラインの進行状況を監視できます。
- サーバレスです。コンピュートリソースを自分でプロビジョニングする必要はありません。
提供元:https://www.youtube-nocookie.com/embed/QX8stvTQ57o
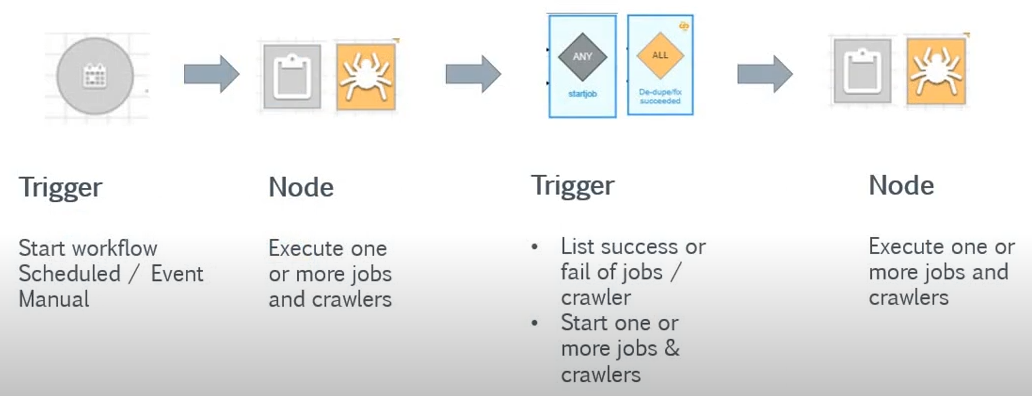
主なコンポーネントは2つ
ワークフローの主なコンポーネントは2つ。トリガーとノードです。
- トリガー
-
- ワークフローやクローラー、ジョブの実行をキックします。
- 手動、イベント、スケジュールのいずれかに基づいて開始します。
- ノード
-
ジョブやクローラーを実行する主体となります。
ワークフローの設計
提供元:https://www.youtube-nocookie.com/embed/QX8stvTQ57o
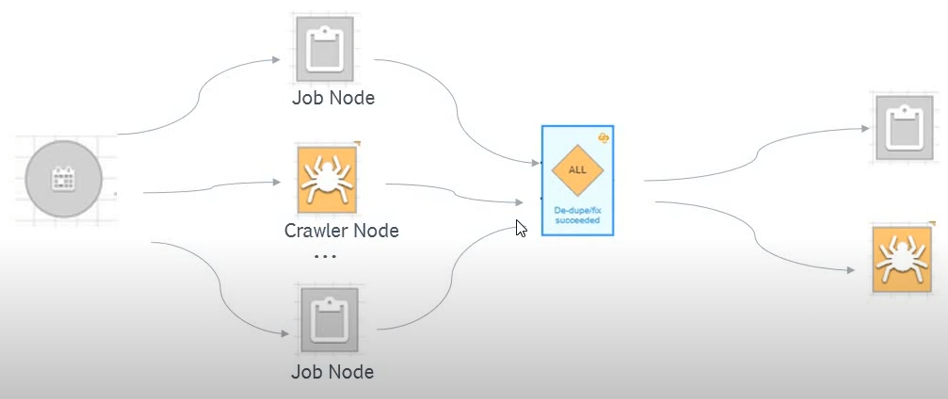
最初のトリガーだけ「手動」「スケジュール」「イベント」に基づいて開始しますが、2つ目以降のトリガーは前のノードの実行結果に基づいて開始します。
ワークフローは、「分岐」と「マージ」を提供します。
提供元:https://www.youtube-nocookie.com/embed/QX8stvTQ57o
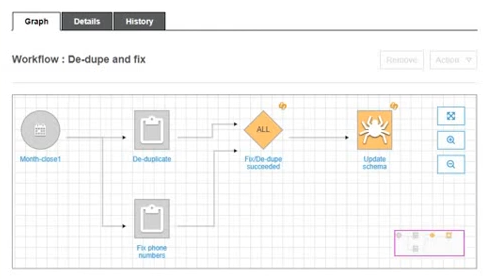
上の例では以下のフローになります。
- ワークフローはスケジュールから開始され、2つのジョブと1つのクローラーを並列で実行する
- ALLトリガーは、前にある2つのジョブと1つのクローラ―がすべて終了したら実行される
- ALLトリガーから1つのジョブと1つのクローラーを並列実行する
ワークフロープロパティ
- 1つのプロパティはキーとバリューのペアで構成され、ワークフロー内で共有する
- ワークフロー内のすべてのジョブがビジネスロジックに利用できる
- ジョブはプロパティの値を取得したり、更新したりできる
ハンズオン
今回の内容です。
- Glueクローラーとジョブをオーケストレイトするワークフローを作成
開始前の状況
これまでのハンズオンで以下の状態になっています。
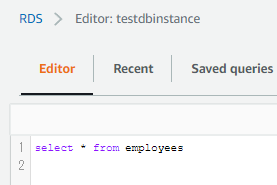
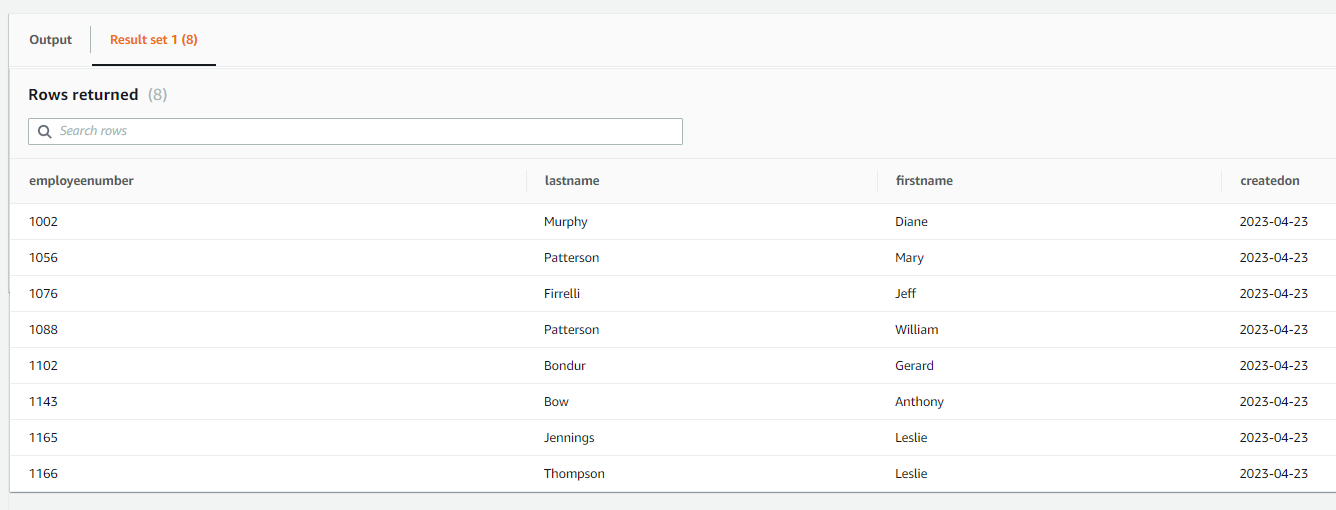
RDS
サーバレスのtestdbinstanceテーブルにemploysテーブルが存在します。
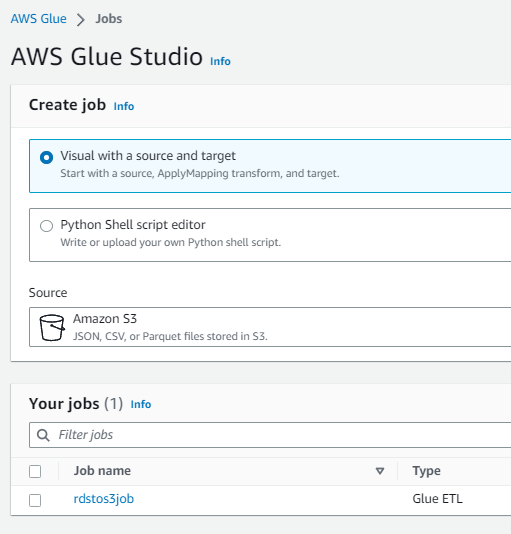
Glue
RDS(testdbinstanceデータベース)のemployeesテーブルのレコードをfirstname列とlastname列のみSELECTして、S3のemployeesフォルダに書き込むETLジョブrdstos3jobが存在します。
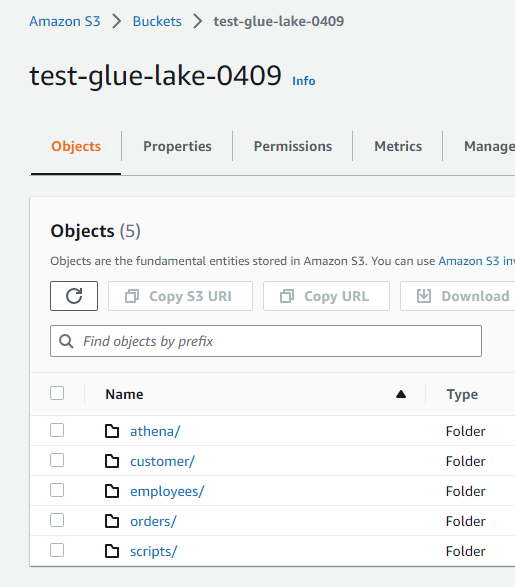
S3
employeesフォルダ配下に、Glueジョブによって作成されたファイルが存在します。
Lake Formation
データカタログされたemployeesテーブルが存在します。
[S3] employeesフォルダ配下を空にする
![[S3] employeesフォルダ配下を空にする1](https://techuplabo.blog/wp-content/uploads/2023/04/image-341.png)
![[S3] employeesフォルダ配下を空にする2](https://techuplabo.blog/wp-content/uploads/2023/04/image-343.png)
[Lake Formation] データカタログのemployeesテーブルを削除
![[Lake Formation] データカタログのemployeesテーブルを削除1](https://techuplabo.blog/wp-content/uploads/2023/04/image-344.png)
Drop権限がないと怒られます。。
![[Lake Formation] データカタログのemployeesテーブルを削除2](https://techuplabo.blog/wp-content/uploads/2023/04/image-345.png)
権限を与えます。
![[Lake Formation] データカタログのemployeesテーブルを削除3](https://techuplabo.blog/wp-content/uploads/2023/04/image-346.png)
ログインしたIAMユーザに、(データカタログの)employeesテーブルへのDrop権限を与えます。

あくまでデータカタログのテーブルに対するDROPね。
![[Lake Formation] データカタログのemployeesテーブルを削除4](https://techuplabo.blog/wp-content/uploads/2023/04/image-347.png)
再びemployeesテーブルのDropを試行します。
![[Lake Formation] データカタログのemployeesテーブルを削除5](https://techuplabo.blog/wp-content/uploads/2023/04/image-348.png)
今度は削除できました。
![[Lake Formation] データカタログのemployeesテーブルを削除6](https://techuplabo.blog/wp-content/uploads/2023/04/image-349.png)
[Glue] ワークフロー作成および実行
今回はプロパティ追加することなく、単純なワークフローを構築します。
![[Glue] ワークフロー作成および実行1](https://techuplabo.blog/wp-content/uploads/2023/04/image-350.png)
作成したワークフローにロジックを追加します。
![[Glue] ワークフロー作成および実行2](https://techuplabo.blog/wp-content/uploads/2023/04/image-352.png)
ワークフロー開始のためのトリガーを追加します。
![[Glue] ワークフロー作成および実行3](https://techuplabo.blog/wp-content/uploads/2023/04/image-353.png)
今回はオンデマンドでトリガー実行とします。
![[Glue] ワークフロー作成および実行4](https://techuplabo.blog/wp-content/uploads/2023/04/image-354.png)
ワークフローグラフが表示されますので「Add Node」を押下します。
![[Glue] ワークフロー作成および実行5](https://techuplabo.blog/wp-content/uploads/2023/04/image-355.png)
rdscrawlerを追加します。
![[Glue] ワークフロー作成および実行6](https://techuplabo.blog/wp-content/uploads/2023/04/image-356.png)
続いてトリガーを追加します。
![[Glue] ワークフロー作成および実行7](https://techuplabo.blog/wp-content/uploads/2023/04/image-357.png)
前のイベントが1つしかないので、ここではどちらでもよいです。「Any」を選択します。
![[Glue] ワークフロー作成および実行8](https://techuplabo.blog/wp-content/uploads/2023/04/image-359.png)
続いてrdstos3jobを追加します。
![[Glue] ワークフロー作成および実行9](https://techuplabo.blog/wp-content/uploads/2023/04/image-360.png)
![[Glue] ワークフロー作成および実行10](https://techuplabo.blog/wp-content/uploads/2023/04/image-361.png)
ワークフローが完成したので実行します。
![[Glue] ワークフロー作成および実行11](https://techuplabo.blog/wp-content/uploads/2023/04/image-362.png)
実行開始したらHistoryへ移動してみましょう。
![[Glue] ワークフロー作成および実行12](https://techuplabo.blog/wp-content/uploads/2023/04/image-363.png)
「View run details」を押下すると、実行状況を確認できます。

![[Glue] ワークフロー作成および実行13](https://techuplabo.blog/wp-content/uploads/2023/04/image-365.png)
ワークフローの実行を完了しました。
![[Glue] ワークフロー作成および実行14](https://techuplabo.blog/wp-content/uploads/2023/04/image-366.png)
[Lake Formation] テーブル追加の確認
データカタログのemployeesテーブルが追加されていることが確認できます。
![[Glue] ワークフロー作成および実行15](https://techuplabo.blog/wp-content/uploads/2023/04/image-367.png)
[S3] データ追加の確認
employeesフォルダ配下にデータが追加されていることが確認できます。
![[Glue] ワークフロー作成および実行16](https://techuplabo.blog/wp-content/uploads/2023/04/image-368.png)
以上、Glueワークフローを用いて、RDSのテーブルからデータカタログのemployeesテーブルを作成し、データをS3にコピーすることが出来ました。
おわりに
今回は、特定のGlueジョブとGlueクローラーを組み合わせたETLパイプラインとして、Glueワークフローを構築しました。


コメント
コメント一覧 (1件)
[…] AWS GlueとLake Formationを試してみた(Vol.7) 前回のハンズオンの続きです。 […]